CWV Superpowers: automatische Core Web Vitals-diagnose
Een gratis Claude Code-skill die verbinding maakt met je CoreDash field data en Chrome om LCP-, INP- en CLS-problemen te diagnosticeren en code-fixes te genereren.

CWV Superpowers is een gratis, open-source Claude Code skill die verbinding maakt met je CoreDash field data en Chrome browser tools om Core Web Vitals problemen te diagnosticeren. Het identificeert je grootste bottleneck in echte gebruikersdata, spoort de bronoorzaak op en genereert de codefix. Geen lijst met Lighthouse-suggesties. Het element, het bestand, de regel code.
Laatst beoordeeld door Arjen Karel in maart 2026
Quickstart:
De code staat op GitHub. Installeer het in Claude Code met twee commando's:
/* Installeer de MarketPlace en de CWV SuperPower Skill */ /plugin marketplace add corewebvitals/cwv-superpowers /plugin install cwv-superpowers@cwv-superpowers /* start nu de Core Web Vitals AI-superkracht */ Waarom is mijn site traag?
Voeg daarna CoreDash toe als een MCP-server en voer claude --chrome uit. Dat is alles.
Wat de CWV SuperPower-skill doet
CWV Superpowers combineert twee databronnen die samen antwoord geven op zowel wat er traag is als waarom.
CoreDash Real User Monitoring vertelt je wat er daadwerkelijk traag is. Echte gebruikers, echte apparaten, echte netwerken. CoreDash registreert elke paginalading en koppelt elke metriek aan het exacte element dat het probleem veroorzaakt. Als het zegt dat je LCP 4,2 seconden is en het bottleneck-element div.hero > img.main is, is dat wat je echte gebruikers ervaren.
Chrome browser tracing vertelt je waarom. De skill bezoekt de pagina met mobiele emulatie (4G, 4x CPU-throttling), registreert de netwerkwaterval en traceert de exacte fasen die RUM-data heeft geïdentificeerd. Niet alles, alleen het deel waarvan is bewezen dat het je pagina's traag maakt!
Dat is de truc! RUM-data vertelt je wat er traag is, maar niet waarom. Een Chrome-trace geeft je het waarom, maar zonder field data onderzoek je de verkeerde pagina of de verkeerde metriek. CWV Superpowers combineert beide.
Het diagnosticeert alle drie de Core Web Vitals: LCP (uitsplitsing in vier fasen), INP (uitsplitsing in drie fasen met script-attributie) en CLS (patroonherkenning voor bekende oorzaken). Zie voor de volledige metriekspecifieke workflows de LCP-diagnosegids en INP-diagnosegids.
De workflow in 5 stappen
Elk onderzoek volgt vijf stappen.
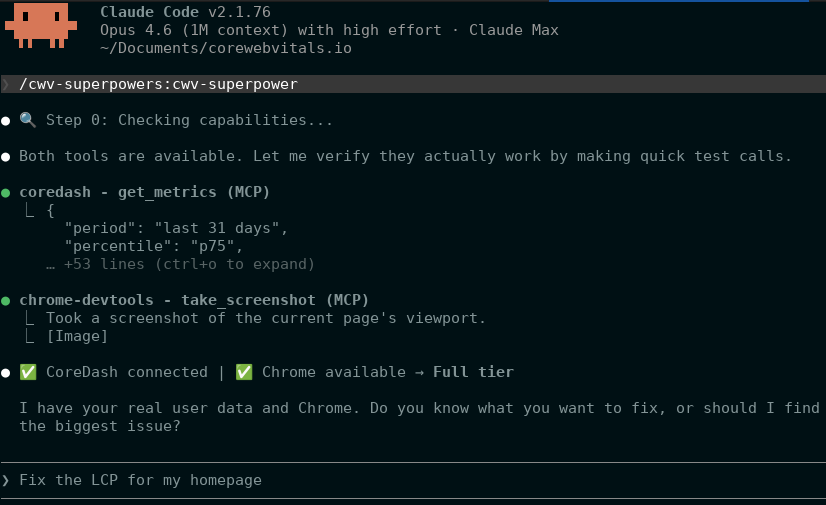
Stap 1: Intentie. Je vertelt waar het naar moet kijken ("LCP op mijn productpagina's") of vraagt het om het probleem te zoeken ("Wat moet ik eerst oplossen?"). Als je iets specifieks noemt, verduidelijkt het de scope. Als je discovery wilt, gaat het naar Stap 2.
Stap 2: Discovery. De skill scant je site via CoreDash. Het haalt de algehele gezondheid, de mobiele gezondheid, de slechtste URL's op basis van LCP en de slechtste op basis van INP op. Vervolgens kiest het het grootste probleem: slechte beoordelingen boven 'verbetering vereist', mobiel boven desktop, hoger verkeersvolume. Een pagina met een p75 LCP van 2,4 seconden die 'slaagt' maar waarvan 18% van de gebruikers in de categorie 'slecht' valt, is nog steeds een probleem. CWV Superpowers signaleert dat.
Stap 3: Diagnose. Voor LCP doet het 5 tot 7 CoreDash API-calls: het LCP-element, het elementtype, de prioriteitsstatus, de uitsplitsing in vier fasen (TTFB, laadvertraging, laadtijd, rendervertraging) en de trend over 7 dagen. Het identificeert de bottleneck met behulp van proportioneel redeneren: de fase die het grootste deel van de totale tijd in beslag neemt, niet de fase die een absolute drempelwaarde overschrijdt. Voor INP haalt het het trage interactie-element, de LOAF-scripts en de uitsplitsing in drie fasen op. Voor CLS matcht het met vijf bekende patronen van oorzaken.
Stap 4: Chrome-trace. Als Chrome beschikbaar is, bezoekt de skill de pagina en traceert alleen de bottleneck-fase uit Stap 3. Een gerichte trace levert bewijs op. Een volledige trace van alles genereert ruis.
Stap 5: Output. Pas de codefix toe, genereer een HTML-rapport, of beide. De fix noemt het bestand, de regel, het element en toont voor en na.
Hoe de output eruitziet
De skill genereert een bronoorzaakverklaring die field data, Chrome-bewijs en de specifieke fix met elkaar verbindt:
Bronoorzaak: De LCP-afbeelding div.hero-banner > img.product-main op /product/running-shoes-42 is 1.980 ms te laat ontdekt omdat deze een preload-hint mist en geen fetchpriority="high" heeft. CoreDash-data: LCP is 3.820 ms (slecht) op mobiel, p75. Laadvertraging is de bottleneck met 52% van het totaal. Chrome-trace bevestigt: een gat van 1.940 ms tussen de HTML first byte en de afbeeldingsaanvraag in de netwerkwaterval.
De fix volgt hier direct uit: voeg een preload-hint toe, stel fetchpriority="high" in. Specifiek voor het element, het bestand en de oorzaak. Geen generiek advies.
Volledige rapporten bevatten metrics-kaarten met kleurgecodeerde beoordelingen, grafieken met de fasen-uitsplitsing, en indien Chrome is gebruikt, filmstrip-screenshots en een netwerkwaterval-SVG. Beide rapporttypes zijn op zichzelf staande HTML-bestanden die je zo in een Slack-thread kunt plaatsen of aan een ticket kunt koppelen.
Tip: Chrome is optioneel. Zonder Chrome krijg je nog steeds een volledige RUM-diagnose, bottleneck-identificatie en codefixes. Je mist de filmstrip- en waterval-visualisaties, maar de kwaliteit van de diagnose is hetzelfde omdat echte gebruikersdata de primaire bron van waarheid is.
Aan de slag
Je hebt een CoreDash-account nodig waar echte gebruikersdata binnenstroomt. De gratis versie is voldoende. Voor interactief gebruik heb je helemaal geen API-key nodig; Claude Code logt in via de browser. Als je toch een key wilt (voor headless- of CI-runs), haal er dan een op via Project Settings > API Keys (MCP). Keys worden eenmalig getoond, opgeslagen als een SHA-256-hash en zijn read-only.
Claude Code (aanbevolen)
# Voeg CoreDash MCP-server toe (browser-login, geen API-key) claude mcp add --transport http coredash https://app.coredash.app/api/mcp # Voeg de skill toe vanuit de marketplace /plugin marketplace add corewebvitals/cwv-superpowers /plugin install cwv-superpowers@cwv-superpower # Start met Chrome voor een volledige analyse claude --chrome
Bij de eerste verbinding voer je /mcp uit, selecteer je coredash en kies je Authenticate. Je browser opent de CoreDash login- en toestemmingspagina; log in, kies een project en accepteer. Claude Code slaat een tijdelijk OAuth-token op dat zichzelf ververst (1 uur toegang, 30 dagen vernieuwing) en herroepbaar blijft. Vraag vervolgens: "Wat zijn mijn Core Web Vitals?" Als het je echte LCP-, INP- en CLS-data teruggeeft, ben je klaar.
Gebruik je liever een API-key, of draai je headless zonder browser? Geef dan de Bearer-header mee:
claude mcp add --transport http coredash https://app.coredash.app/api/mcp \ --header "Authorization: Bearer cdk_YOUR_API_KEY"
Cursor
Voeg CoreDash toe aan .cursor/mcp.json:
{
"mcpServers": {
"coredash": {
"url": "https://app.coredash.app/api/mcp",
"headers": {
"Authorization": "Bearer cdk_YOUR_API_KEY"
}
}
}
}
Andere MCP-clients
De CoreDash MCP-server werkt met elke client die HTTP MCP ondersteunt: VS Code (Copilot agent-modus), Windsurf, Gemini CLI, Cline en JetBrains IDEs. Het eindpunt is https://app.coredash.app/api/mcp met een Bearer-token-header. Zie de installatiegids op GitHub voor de configuratie per client.
Lees het overzichtsartikel voor achtergrondinformatie over waarom field data belangrijk is voor het Core Web Vitals-werk van AI-agents en waarom Lighthouse-only agents fixes opleveren die in een derde van de gevallen worden afgewezen.
Je Lighthouse-score vertelt niet alles.
Je echte bezoekers zitten op een Android via 4G. Ik kijk naar wat zij meemaken.
Analyseer echte data
