Risolvere e Identificare i Problemi del Time to First Byte (TTFB)
Scopri come eseguire il debug dei problemi del Time to First Byte sulle tue pagine utilizzando i dati RUM, le intestazioni Server-Timing e l'analisi sistematica delle sotto-parti del TTFB

Trova e Risolvi i Problemi del Time to First Byte (TTFB)
Questo articolo fa parte della nostra guida sul Time to First Byte (TTFB). Il TTFB è una metrica diagnostica che misura il tempo trascorso tra la richiesta di una pagina da parte di un utente e la ricezione del primo byte della risposta da parte del browser. Sebbene il TTFB non sia un Core Web Vital di per sé, influenza direttamente sia il First Contentful Paint (FCP) che il Largest Contentful Paint (LCP). Un buon TTFB è inferiore a 800 millisecondi al 75° percentile.
Nel nostro articolo precedente abbiamo parlato del Time to First Byte. Se desideri approfondire le basi, è un ottimo punto di partenza.
In questo articolo ci concentreremo sull'identificazione dei diversi problemi del Time to First Byte e spiegheremo come risolverli.
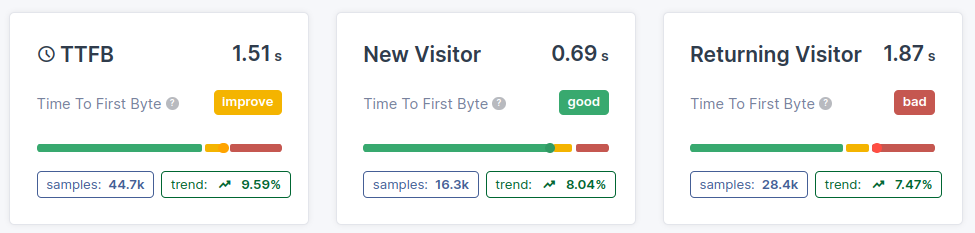
SUGGERIMENTO TTFB: la maggior parte delle volte il TTFB sarà molto peggiore per i nuovi visitatori, poiché non hanno una cache DNS per il tuo sito. Quando si traccia il TTFB, ha molto senso distinguere tra i visitatori alla prima visita e quelli di ritorno.
Table of Contents!
- Trova e Risolvi i Problemi del Time to First Byte (TTFB)
- Passo 1: Controlla il TTFB in Search Console
- Passo 1b: Utilizza l'intestazione Server-Timing per Analisi più Approfondite
- Passo 2: Configura il Tracciamento RUM
- Passo 2b: Stabilisci una Baseline delle Performance
- Passo 3: Identifica i Problemi del Time to First Byte
- Passo 4: Analizza da Vicino i Problemi e Risolvili
- Passo 5: Checklist delle Soluzioni Rapide per i Problemi Comuni del TTFB
- Misurare il TTFB con JavaScript
- Letture di Approfondimento: Guide all'Ottimizzazione
- Sotto-parti del TTFB: Guide Complete
Passo 1: Controlla il TTFB in Search Console
"Il primo passo per guarire è ammettere di avere un problema." Quindi, prima di fare qualsiasi cosa per migliorare il Time to First Byte, assicuriamoci di avere davvero un problema con il TTFB.
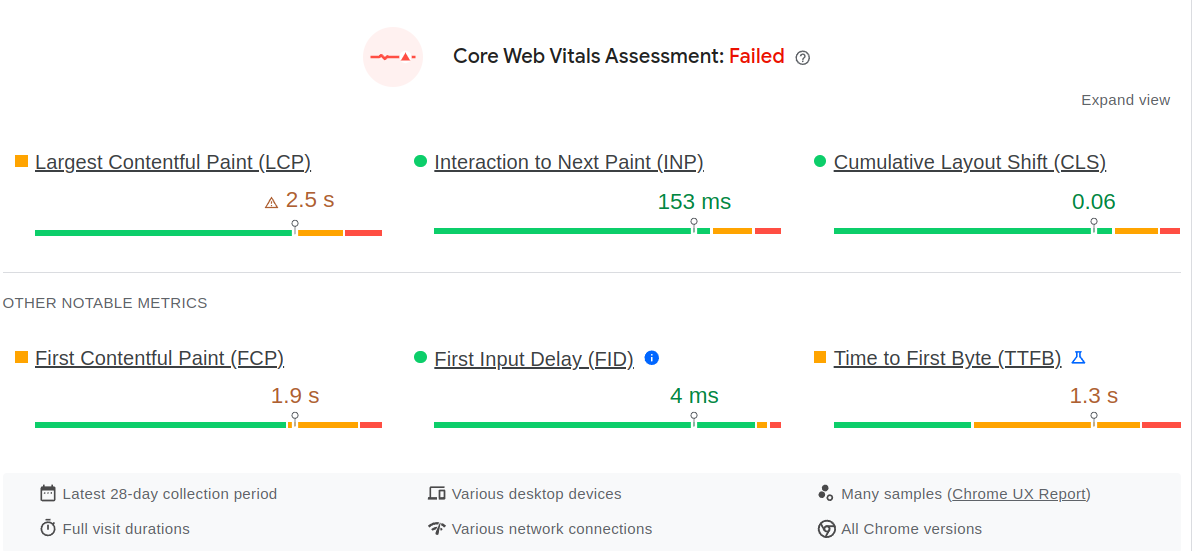
Sfortunatamente, il Time to First Byte non viene riportato in Google Search Console, quindi dobbiamo affidarci a pagespeed.web.dev per interrogare i dati CrUX del nostro sito. Fortunatamente, i passaggi sono semplici: naviga su pagespeed.web.dev, inserisci l'URL della tua pagina e assicurati che il pulsante "origin" sia selezionato (poiché abbiamo bisogno dei dati dell'intero sito e non solo della homepage). Ora passa da Mobile a Desktop e controlla il Time to First Byte per entrambi i tipi di dispositivo.
Nell'esempio sottostante vedrai un sito che non supera i Core Web Vitals a causa di un TTFB elevato.
Passo 1b: Utilizza l'intestazione Server-Timing per Analisi più Approfondite
L'intestazione HTTP di risposta Server-Timing consente al tuo server di comunicare le metriche di performance del backend direttamente al browser. Questo permette di individuare esattamente quale parte dell'elaborazione del server è lenta senza aver bisogno di accedere ai log del server.
Una tipica intestazione Server-Timing si presenta così:
Server-Timing: db;dur=53, app;dur=120, cache;desc="miss"
In questo esempio, il server riporta tre valori di tempistica:
- db;dur=53: la query al database ha impiegato 53 millisecondi.
- app;dur=120: la logica dell'applicazione (rendering dei template, chiamate API, ecc.) ha impiegato 120 millisecondi.
- cache;desc="miss": la cache del server non è stata utilizzata per questa richiesta (un miss della cache).
Puoi leggere questi valori nei Chrome DevTools aprendo la scheda Network, selezionando la richiesta del documento e scorrendo fino alla sezione "Server Timing" nella scheda Timing. I valori sono accessibili anche tramite l'API PerformanceServerTiming in JavaScript:
const [navigation] = performance.getEntriesByType('navigation');
if (navigation.serverTiming) {
navigation.serverTiming.forEach(entry => {
console.log(`${entry.name}: ${entry.duration}ms (${entry.description})`);
});
}
Se il tuo server non invia ancora le intestazioni Server-Timing, valuta di aggiungerle. La maggior parte dei framework web rende questa operazione molto semplice. In PHP puoi aggiungere l'intestazione prima di qualsiasi output:
header('Server-Timing: db;dur=' . $dbTime . ', app;dur=' . $appTime);
In Node.js con Express:
res.setHeader('Server-Timing', `db;dur=${dbTime}, app;dur=${appTime}`);
L'intestazione Server-Timing è particolarmente utile quando combinata con il Real User Monitoring perché ti consente di correlare le performance lato server con il TTFB riscontrato dagli utenti reali. Scopri di più su come le 103 Early Hints possono ridurre ulteriormente il TTFB percepito inviando suggerimenti sulle risorse prima che l'intera risposta sia pronta.
Passo 2: Configura il Tracciamento RUM
Il Time to First Byte è una metrica complessa. Non possiamo semplicemente affidarci ai test sintetici per misurare il TTFB, perché nella vita reale altri fattori contribuiranno alle sue fluttuazioni. Per ottenere risposte a tutte le domande precedenti, dobbiamo misurare i dati nel mondo reale e registrare tutti i problemi che potrebbero verificarsi con il Time to First Byte. Questo si chiama Real User Monitoring (RUM) e ci sono diversi modi per abilitare il tracciamento RUM. Abbiamo sviluppato CoreDash proprio per questi casi d'uso. CoreDash è uno strumento RUM a basso costo, veloce ed efficace che fa il suo dovere. Naturalmente, esistono molte altre soluzioni RUM che faranno altrettanto bene il lavoro (a un prezzo più elevato, tuttavia).
Come pensare al TTFB: Immagina che un server web sia la cucina di un ristorante e che un utente che richiede una pagina web sia un cliente affamato che effettua un ordine. Il Time to First Byte (TTFB) è l'intervallo di tempo che intercorre tra il cliente che effettua l'ordine e la cucina che inizia a preparare il cibo.
Quindi il TTFB NON riguarda la velocità con cui l'intero pasto viene cucinato (First Contentful Paint) e servito (Largest Contentful Paint), ma piuttosto la reattività della cucina alla richiesta iniziale.
Il Tracciamento RUM è paragonabile a intervistare i clienti per capire la loro esperienza culinaria. Potresti scoprire che i clienti seduti più lontano dalla cucina ricevono meno attenzione dal cameriere e vengono serviti più tardi, o che i clienti abituali ottengono un trattamento di favore mentre i nuovi visitatori devono aspettare più a lungo per un tavolo.
Passo 2b: Stabilisci una Baseline delle Performance
Prima di apportare qualsiasi modifica, stabilisci una baseline per il tuo TTFB. Registra il 75° percentile del TTFB su queste dimensioni, poiché ti aiuterà a misurare l'efficacia delle tue ottimizzazioni in un secondo momento:
- TTFB Complessivo (mobile e desktop separatamente): acquisisci il 75° percentile per ciascun tipo di dispositivo.
- Top 10 delle pagine per traffico: registra il TTFB individualmente per le tue pagine con più traffico.
- Nuovi visitatori vs visitatori abituali: i visitatori alla prima visita in genere presentano un TTFB più elevato a causa dell'overhead del DNS e della connessione.
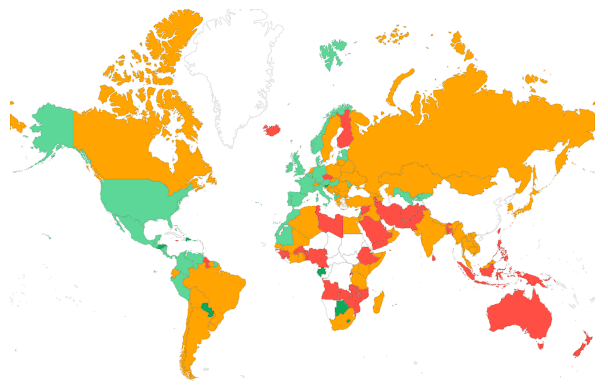
- Top 5 dei paesi per traffico: la distanza geografica dal tuo server influisce in modo significativo sul TTFB.
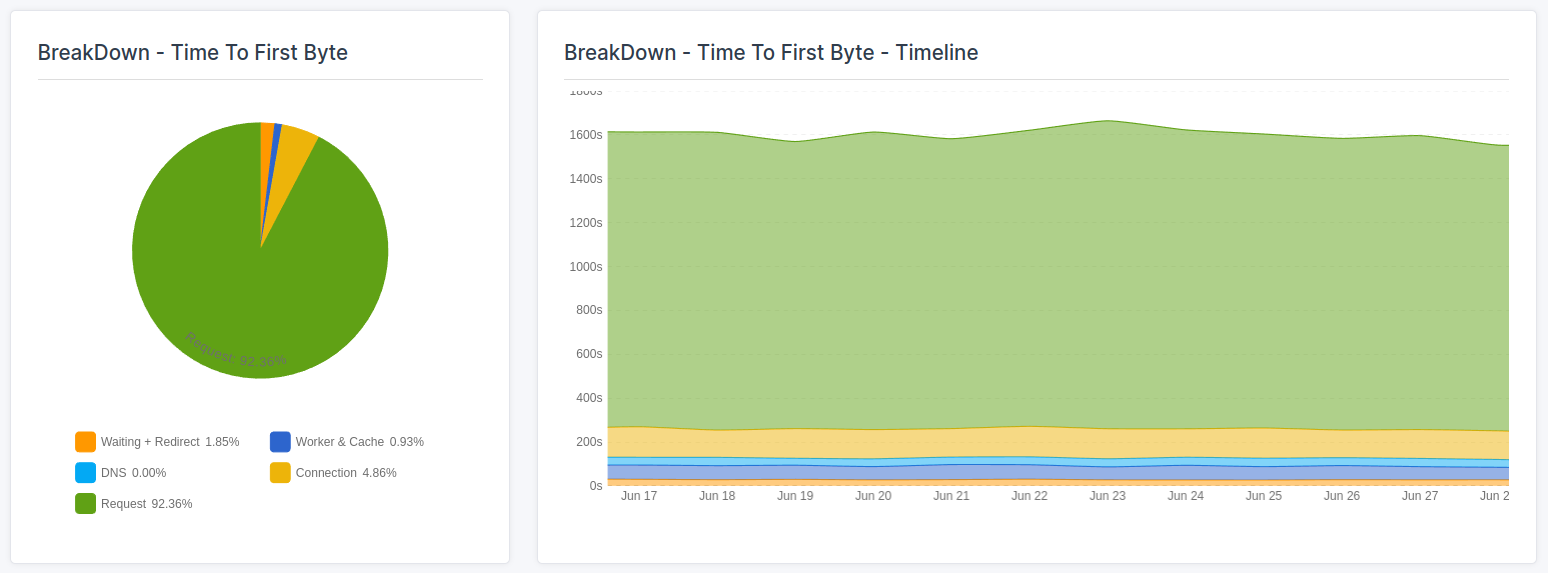
- Ripartizione delle sotto-parti del TTFB: registra il 75° percentile per ciascuna sotto-parte (attesa, cache, DNS, connessione, richiesta).
Documenta questi numeri in un foglio di calcolo. Dopo aver implementato ogni ottimizzazione, attendi almeno 7 giorni per raccogliere dati RUM sufficienti prima di confrontare i risultati. Un buon approccio è affrontare una singola sotto-parte del TTFB alla volta, misurare, e poi passare alla successiva.
Passo 3: Identifica i Problemi del Time to First Byte
Sebbene il Chrome User Experience Report (CrUX) di Google fornisca preziosi dati sul campo, non offre dettagli specifici sulle cause di un TTFB elevato. Per migliorare efficacemente il TTFB, dobbiamo sapere esattamente cosa sta succedendo a un livello più dettagliato. A questo punto, ha senso distinguere tra un TTFB complessivamente insufficiente e un TTFB insufficiente in condizioni specifiche (anche se nella realtà ci sarà sempre una via di mezzo).
3.1 Il TTFB è Complessivamente Insufficiente
- Controlla i "tempi di richiesta" generalmente lenti: Tempi di richiesta scadenti significano che il "problema" risiede nel tempo impiegato dal server per generare la pagina. Questa è la causa più comune di scarsi punteggi TTFB.
- Controlla le altre sotto-parti lente del TTFB: Il TTFB non è solo una singola metrica, ma può essere suddiviso in più parti, ognuna con il proprio potenziale di ottimizzazione. Se la durata dell'attesa, la durata della cache, la durata della risoluzione DNS o la durata della connessione sono lente, molto probabilmente dovrai ottimizzare le impostazioni del tuo server o iniziare a cercare un hosting di qualità migliore.
3.2 Il TTFB è Insufficiente in Condizioni Specifiche
- Segmentazione per paese: Comprendere la distribuzione geografica di un TTFB elevato è importante, soprattutto per i siti web con un pubblico globale. Se stai fornendo le tue pagine da un singolo server in un solo paese (senza un edge caching CDN), la distanza fisica tra la posizione dell'utente e il server che ospita il sito web causerà ogni sorta di ritardi e avrà un impatto sul TTFB. Prendi in considerazione la configurazione di Cloudflare o di un'altra CDN per avvicinare i tuoi contenuti agli utenti di tutto il mondo.
- Segmentazione per cache: Il caching può ridurre il TTFB saltando la generazione lato server dell'HTML. Purtroppo, è comune che la cache sia disabilitata o bypassata per molte ragioni. Ad esempio, la cache può essere disabilitata per gli utenti che hanno effettuato l'accesso, per le pagine del carrello, per le pagine con stringhe di query (es. da Google Ads), per le pagine dei risultati di ricerca e per le pagine di checkout. Se il tuo sito web utilizza il caching (edge), sfrutta il tracciamento RUM per verificare il rapporto di hit della cache.
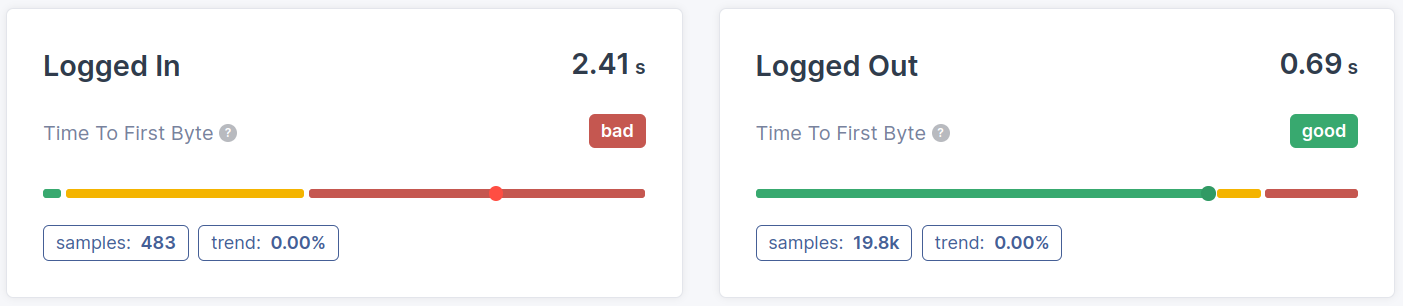
- Segmentazione per pagine (cluster): La differenza nelle performance del Time to First Byte (o la mancanza di differenza) tra le pagine o le tipologie di pagina è un altro elemento che dobbiamo determinare. Sapere quali pagine non superano la metrica del TTFB fornirà indicazioni preziose su come migliorare il Time to First Byte.
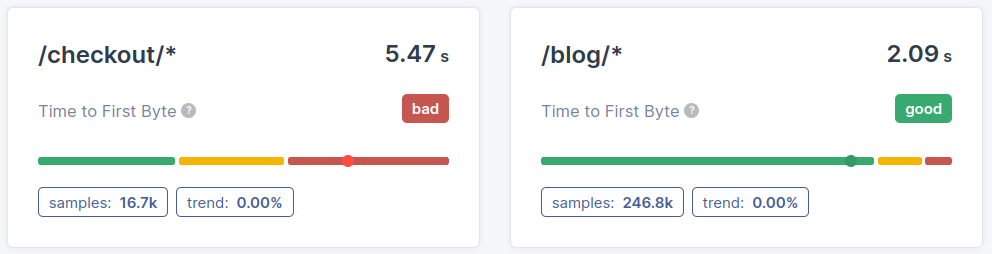
- Segmentazione dei reindirizzamenti: Il tempo di reindirizzamento si aggiunge direttamente al TTFB. Ogni reindirizzamento aggiunge tempo extra prima che il server web possa iniziare a caricare la pagina. Misurare ed eliminare i reindirizzamenti non necessari può aiutare a migliorare il TTFB. Per un'analisi più approfondita sull'ottimizzazione dei reindirizzamenti, consulta la nostra guida sulla sotto-parte della durata dell'attesa del TTFB.

- Altra segmentazione: Sebbene la segmentazione per le variabili indicate sopra copra i classici indiziati, ogni sito è unico e presenta le proprie sfide. Fortunatamente, il tracciamento RUM è progettato per consentire la segmentazione in base a molte altre variabili, come la RAM del Dispositivo, la Velocità di Rete, il Tipo di Dispositivo, il Sistema Operativo, le variabili personalizzate e molto altro ancora.
Passo 4: Analizza da Vicino i Problemi e Risolvili
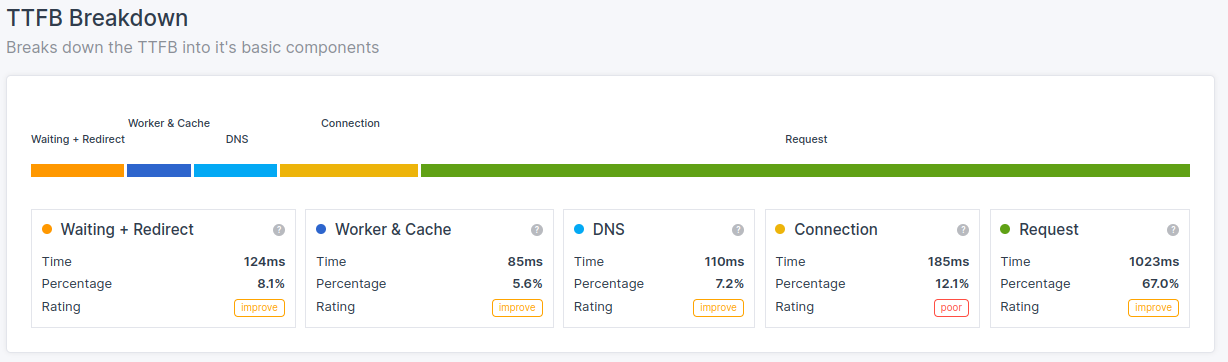
Le sotto-parti del Time to First Byte (TTFB) sono:
- Attesa + Redirect (o durata dell'attesa)
- Worker + Cache (o durata della cache)
- DNS (o durata del DNS)
- Connessione (o durata della connessione)
- Richiesta (o durata della richiesta)
Passo 5: Checklist delle Soluzioni Rapide per i Problemi Comuni del TTFB
In base alla sotto-parte che contribuisce maggiormente al tuo TTFB, ecco un rapido riferimento per le soluzioni più comuni:
| Sotto-parte del TTFB | Causa Più Comune | Soluzione Rapida |
|---|---|---|
| Durata dell'attesa | Reindirizzamenti non necessari | Esamina ed elimina le catene di reindirizzamento; implementa HSTS |
| Durata della cache | Avvio lento del service worker | Semplifica il codice del service worker; usa strategie di caching efficienti |
| Durata del DNS | Provider DNS lento | Passa a un provider DNS premium come Cloudflare; regola le impostazioni TTL |
| Durata della connessione | Versione TLS obsoleta | Abilita TLS 1.3 e HTTP/3; usa una CDN per la prossimità |
| Durata della richiesta | Elaborazione lenta del server | Implementa il caching lato server; ottimizza le query al database; usa le 103 Early Hints |
Misurare il TTFB con JavaScript
Puoi misurare il TTFB completo e le sue sotto-parti direttamente nel browser utilizzando la Navigation Timing API. Il seguente snippet calcola il TTFB e registra ogni sotto-parte:
new PerformanceObserver((entryList) => {
const [nav] = entryList.getEntriesByType('navigation');
const activationStart = nav.activationStart || 0;
const ttfb = nav.responseStart - activationStart;
const waitingDuration = (nav.workerStart || nav.fetchStart) - activationStart;
const cacheDuration = nav.domainLookupStart - (nav.workerStart || nav.fetchStart);
const dnsDuration = nav.domainLookupEnd - nav.domainLookupStart;
const connectionDuration = nav.connectEnd - nav.connectStart;
const requestDuration = nav.responseStart - nav.requestStart;
console.log('TTFB:', ttfb.toFixed(0), 'ms');
console.log(' Waiting:', waitingDuration.toFixed(0), 'ms');
console.log(' Cache:', cacheDuration.toFixed(0), 'ms');
console.log(' DNS:', dnsDuration.toFixed(0), 'ms');
console.log(' Connection:', connectionDuration.toFixed(0), 'ms');
console.log(' Request:', requestDuration.toFixed(0), 'ms');
}).observe({
type: 'navigation',
buffered: true
});
Questo codice fornisce la stessa ripartizione che strumenti come CoreDash mostrano nel pannello di attribuzione del TTFB. Eseguire questo frammento di codice nella console del browser ti dà una lettura immediata per il singolo caricamento della pagina, mentre gli strumenti RUM raccolgono questi dati su migliaia di utenti reali per produrre valori affidabili al 75° percentile.
Letture di Approfondimento: Guide all'Ottimizzazione
Guide correlate:
- 103 Early Hints: invia suggerimenti sulle risorse prima che la risposta completa sia pronta, consentendo al browser di iniziare a caricare risorse critiche mentre il server sta ancora elaborando.
- Configurare Cloudflare per le Performance: imposta la CDN, il caching e le funzionalità edge di Cloudflare per ridurre il TTFB per i segmenti di pubblico globali.
Sotto-parti del TTFB: Guide Complete
Ogni sotto-parte del Time to First Byte ha le proprie strategie di ottimizzazione. Inizia con la sotto-parte che i tuoi dati RUM identificano come collo di bottiglia:
- Durata dell'Attesa: reindirizzamenti, accodamento del browser e ottimizzazione HSTS.
- Durata della Cache: performance del service worker, cache del browser e bfcache.
- Durata del DNS: selezione del provider DNS, configurazione del TTL e dns-prefetch.
- Durata della Connessione: handshake TCP, ottimizzazione TLS, HTTP/3 e preconnect.
- Durata della Richiesta: tempo di elaborazione del server, query al database e ottimizzazione del backend.
Codice, non report.
Entro nel tuo team per 1 o 2 sprint. Setto il monitoring e lascio il team in grado di tenere le metriche verdi da solo.
Scrivimi
