Qu'est-ce que le Time To First Byte (TTFB) et comment l'améliorer
Qu'est-ce que le Time to First Byte, pourquoi il est important pour vos Core Web Vitals, et comment l'optimiser

Le Time to First Byte (TTFB) mesure le temps en millisecondes entre le moment où le navigateur demande une page et celui où il reçoit le premier octet de la réponse du serveur. Un bon TTFB est de 800 millisecondes ou moins au 75e percentile. Le TTFB n'est pas un Core Web Vital, mais c'est une métrique de diagnostic critique car elle impacte directement à la fois le Largest Contentful Paint (LCP) et le First Contentful Paint (FCP).
Table of Contents!
- Qu'est-ce que le Time to First Byte
- Le TTFB n'est pas un Core Web Vital
- Pourquoi le Time to First Byte est-il important
- Qu'est-ce qu'un bon score TTFB ?
- Impact concret : l'étude de cas T-Mobile
- Le TTFB de la requête à la réponse
- Mesurer le TTFB avec Server-Timing
- Accélérer le TTFB avec les 103 Early Hints
- Éliminer le TTFB avec l'API Speculation Rules
- Comment l'hébergement affecte-t-il le Time to First Byte ?
- Comment améliorer le TTFB : accélérer la connexion initiale
- Comment améliorer le TTFB : accélérer le côté serveur
- How to improve the TTFB: speed up the client side
- Comment améliorer le TTFB : utiliser un CDN
- Comment améliorer le TTFB : éviter les redirections
- Optimisez la priorisation des ressources parallèlement au TTFB
- Ce que montrent les données réelles sur le TTFB
- Foire aux questions sur le TTFB
- Guides connexes : sous-parties du TTFB
Qu'est-ce que le Time to First Byte
Le Time to First Byte (TTFB) indique le temps qui s'est écoulé en millisecondes entre le début de la requête et la réception de la première réponse (octet) d'une page web. Le TTFB est donc également appelé temps d'attente. Le TTFB est un moyen de mesurer la réactivité d'un serveur web et le chemin réseau entre l'utilisateur et ce serveur. Le TTFB est une métrique fondamentale ; cela signifie que le temps ajouté au TTFB sera également ajouté au Largest Contentful Paint et au First Contentful Paint. Chaque milliseconde économisée sur le TTFB est une milliseconde économisée sur ces deux métriques de rendu.

Le TTFB n'est pas un Core Web Vital
Il est important de le dire clairement : Le TTFB ne fait pas partie des trois Core Web Vitals. Les Core Web Vitals se composent du Largest Contentful Paint (LCP), de l'Interaction to Next Paint (INP), et du Cumulative Layout Shift (CLS). Google n'utilise pas directement le TTFB dans ses signaux de classement de l'expérience utilisateur.
Cependant, le TTFB est classé comme une métrique de diagnostic. Il vous aide à comprendre pourquoi votre LCP ou votre FCP pourrait être lent. Selon le Web Almanac 2025, les sites ayant un mauvais LCP passent en moyenne 2,27 secondes rien que sur le TTFB, ce qui épuise presque entièrement le seuil de 2,5 secondes du LCP avant même que le navigateur ne commence à rendre la page. L'optimisation du TTFB est donc l'une des actions les plus percutantes que vous puissiez entreprendre pour vos scores globaux de Core Web Vitals.
Pourquoi le Time to First Byte est-il important
Le Time to First Byte n'est pas un Core Web Vital et il est tout à fait possible de réussir les Core Web Vitals tout en échouant à la métrique TTFB. Cela ne signifie pas que le TTFB n'est pas important. Le TTFB est une métrique extrêmement importante à optimiser et sa correction améliorera considérablement la vitesse de page et l'expérience utilisateur.
L'impact du TTFB pour les visiteurs
Le Time to First Byte précède toutes les autres métriques de rendu. Pendant que le navigateur attend le Time to First Byte, il ne peut rien faire et affichera simplement un écran blanc. Cela signifie que toute augmentation du Time to First Byte se traduira par un temps d' "écran blanc" supplémentaire et toute diminution du Time to First Byte se traduira par moins de temps d' "écran blanc".
Pour obtenir cette impression de chargement instantané des pages, le Time to First Byte doit être aussi rapide que possible.
Pourquoi le TTFB n'est-il pas un Core Web Vital ? Le TTFB ne tient pas compte du rendu : un TTFB bas ne signifie pas nécessairement une bonne expérience utilisateur car il ne prend pas en compte le temps nécessaire au navigateur pour rendre la page web. Même si tous les octets sont téléchargés rapidement, la page web pourrait encore mettre beaucoup de temps à s'afficher si le navigateur doit traiter beaucoup de JavaScript ou rendre des mises en page complexes.
Qu'est-ce qu'un bon score TTFB ?

Il est recommandé que votre serveur réponde aux requêtes de navigation assez rapidement pour que le 75e percentile des utilisateurs bénéficie d'un FCP dans le seuil "bon". À titre indicatif, la plupart des sites devraient s'efforcer d'avoir un TTFB de 0,8 seconde ou moins.
- Un TTFB inférieur à 800 millisecondes est considéré comme bon.
- Un TTFB compris entre 800 et 1 800 millisecondes nécessite une amélioration.
- Un TTFB supérieur à 1 800 millisecondes est considéré comme médiocre et doit être amélioré immédiatement.
Impact concret : l'étude de cas T-Mobile
T-Mobile a investi massivement dans la réduction de son Time to First Byte dans le cadre d'une initiative plus large d'optimisation des performances. Les résultats ont été frappants : une augmentation de 60 % des conversions visite-commande. En passant à des pages rendues à la périphérie (edge-rendered) et à une mise en cache agressive côté serveur, T-Mobile a considérablement réduit le temps que les utilisateurs passaient à attendre le premier octet, ce qui a entraîné par ricochet un LCP plus rapide, un FCP plus rapide et une expérience utilisateur nettement meilleure. Cette étude de cas démontre que l'optimisation du TTFB n'est pas seulement un exercice technique ; elle affecte directement les résultats commerciaux.
Le TTFB de la requête à la réponse
Du navigateur au serveur : la requête
Le temps de requête du navigateur est le temps écoulé entre le moment où le navigateur d'un utilisateur envoie une requête HTTP et celui où cette requête atteint le serveur hébergeant le site web. Le TTFB de cette partie échappe largement au contrôle direct du site web et dépend fortement de :
- La vitesse Internet de l'utilisateur.
- La qualité de son infrastructure réseau.
- La distance physique entre l'utilisateur et le serveur.
Au cours de cette étape, la recherche DNS, le temps de démarrage du navigateur, les recherches dans le cache du navigateur et la négociation de la connexion au serveur (TCP et TLS) prennent tous un peu de temps.
Sur le serveur : traitement
Une fois que la requête a atteint le serveur, celui-ci doit la traiter et générer la réponse. Le temps nécessaire au serveur pour cette étape est appelé temps de traitement du serveur. Ce temps dépend de plusieurs facteurs, tels que la complexité du site web, l'efficacité du code côté serveur et les ressources disponibles sur le serveur (CPU, RAM). C'est la partie du TTFB sur laquelle vous avez le plus de contrôle.
Du serveur au navigateur : la réponse
Une fois que le serveur a généré la réponse, il doit la renvoyer au navigateur de l'utilisateur. Le temps nécessaire au premier octet de la réponse pour atteindre le navigateur de l'utilisateur est appelé temps de réponse. Tout comme le temps de requête, cette partie du TTFB dépend de la connexion Internet de l'utilisateur et de la distance physique entre l'utilisateur et le serveur.
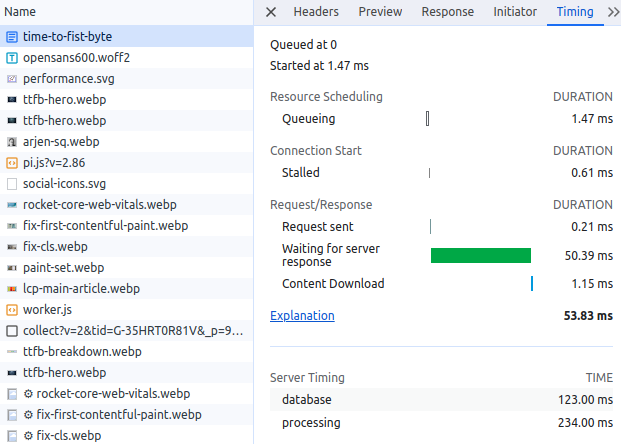
Mesurer le TTFB avec Server-Timing
Pour mesurer le temps de traitement côté serveur, vous pouvez utiliser l'API Server-Timing. Cette API permet aux serveurs d'envoyer des informations sur leurs performances au navigateur, qui peuvent ensuite être consultées dans les outils de développement (DevTools) du navigateur.
L'API Server-Timing fonctionne en envoyant un en-tête de réponse HTTP du serveur au navigateur. Cet en-tête peut contenir plusieurs métriques séparées par des virgules. Chaque entrée se compose de :
- Un nom court pour la métrique (comme
databaseetprocessing) - Une durée en millisecondes (exprimée sous la forme
dur=123) - Une description facultative (exprimée sous la forme
desc="Ma Description")
Server-Timing: database;dur=123;desc="DB Query", processing;dur=234;desc="Template Render", cache;dur=0;desc="Cache HIT"
Lecture de Server-Timing dans les Chrome DevTools
Les Chrome DevTools affichent les entrées Server-Timing directement dans le panneau Network. Ouvrez les DevTools, sélectionnez la requête du document dans l'onglet Network, faites défiler vers le bas jusqu'à la section "Server Timing" dans l'onglet Timing. Chaque métrique que vous envoyez via l'en-tête Server-Timing apparaîtra avec son nom, sa description et sa durée. Cela permet d'identifier facilement si votre base de données, le rendu du modèle ou la couche de mise en cache constitue le goulot d'étranglement.
Vous pouvez également lire l'en-tête Server-Timing par programmation et envoyer ces timings à votre outil RUM préféré comme CoreDash pour un suivi et des alertes à long terme.
Accélérer le TTFB avec les 103 Early Hints
103 Early Hints est un code d'état HTTP qui permet au serveur d'envoyer des en-têtes de réponse préliminaires au navigateur avant que la réponse finale ne soit prête. Pendant que le serveur traite encore la requête (interrogation de la base de données, rendu du modèle), le navigateur peut déjà commencer à charger des ressources critiques telles que les feuilles de style, les polices et l'image LCP.
Comment fonctionnent les 103 Early Hints
Dans un flux de requête traditionnel, le navigateur reste inactif pendant tout le temps de traitement du serveur. Avec les 103 Early Hints, le serveur envoie une réponse partielle immédiatement après avoir reçu la requête. Cette réponse partielle contient des en-têtes Link qui indiquent au navigateur quelles ressources précharger (preload) ou auxquelles se pré-connecter (preconnect). Le navigateur agit sur ces suggestions pendant qu'il attend la réponse 200 complète.
Cela transforme efficacement le temps d'attente mort en temps de chargement productif. Bien que les 103 Early Hints ne réduisent pas le TTFB du document lui-même, ils réduisent l'impact perçu du TTFB sur les métriques suivantes comme le LCP et le FCP en donnant au navigateur une longueur d'avance sur la découverte des ressources.
Exemple de configuration serveur pour les 103 Early Hints
De nombreux CDN et serveurs web supportent désormais les 103 Early Hints. Voici un exemple utilisant Cloudflare, qui génère automatiquement des 103 Early Hints à partir des en-têtes Link et des balises preload/preconnect trouvées dans votre HTML :
HTTP/1.1 103 Early Hints Link: </style.css>; rel=preload; as=style Link: </static/img/hero.webp>; rel=preload; as=image Link: <https://fonts.googleapis.com>; rel=preconnect HTTP/1.1 200 OK Content-Type: text/html ...
Pour Nginx, vous pouvez configurer les Early Hints en ajoutant des en-têtes Link à votre réponse et en activant le push HTTP/2 ou HTTP/3. Apache supporte les 103 Early Hints via la directive H2EarlyHints. Consultez notre guide détaillé sur la mise en œuvre des 103 Early Hints pour des instructions étape par étape.
Éliminer le TTFB avec l'API Speculation Rules
L'API Speculation Rules est conçue pour améliorer les performances des navigations futures. Une fois qu'un visiteur a atterri sur votre page, vous pouvez utiliser les Speculation Rules pour demander au navigateur de récupérer (avec la directive prefetch) ou même de rendre complètement (avec la directive prerender) les pages que le visiteur est le plus susceptible de consulter ensuite.
Comment les Speculation Rules éliminent le TTFB
Lorsqu'une page est pré-rendue (prerendered), le navigateur la charge et la rend complètement dans un onglet masqué. Lorsque l'utilisateur clique ensuite sur le lien, la page pré-rendue est affichée instantanément. Résultat : un TTFB mesuré de 0 milliseconde. Ce n'est pas un chiffre théorique. Les données RUM de CoreDash provenant de corewebvitals.io confirment que les navigations pré-rendues via les Speculation Rules affichent un TTFB p75 de 0 ms.
Le Prefetching est une alternative plus légère. Au lieu de rendre complètement la page, le navigateur récupère uniquement le document HTML et le met en cache. Cela élimine la partie réseau du TTFB tout en exigeant toujours du navigateur qu'il analyse et rende le document lors de la navigation.
Syntaxe JSON des Speculation Rules
Les Speculation Rules sont définies à l'aide d'un bloc <script type="speculationrules"> contenant du JSON. Voici un exemple qui pré-rend tous les liens de navigation de votre barre de menu avec un empressement "modéré" (déclenché au survol ou lors de l'appui sur le pointeur) :
<script type="speculationrules">
{"prerender":
[{
"source": "document",
"where": {"selector_matches": "nav a"},
"eagerness": "moderate"
}]}
</script>
Vous pouvez également utiliser une approche basée sur une liste pour des URL spécifiques :
<script type="speculationrules">
{"prefetch":
[{
"source": "list",
"urls": ["/core-web-vitals/", "/pagespeed/103-early-hints"]
}]}
</script>
Le support des Speculation Rules par les navigateurs se développe. Chrome 121+ supporte l'intégralité de l'API, y compris les règles de document. Pour les navigateurs qui ne supportent pas encore les Speculation Rules, vous pourriez utiliser un script léger comme quicklink comme solution de repli. Utilisez notre Générateur de Speculation Rules pour créer la configuration adaptée à votre site.
Comment l'hébergement affecte-t-il le Time to First Byte ?
L'hébergement affecte le Time to First Byte de plusieurs manières. En investissant dans un meilleur hébergement, il est généralement possible d'améliorer immédiatement le Time to First Byte sans rien changer d'autre. En particulier lors du passage d'un hébergement partagé à petit budget à des serveurs virtuels correctement configurés et gérés, le TTFB pourrait s'améliorer considérablement.
CONSEIL d'hébergement : un meilleur hébergement implique un traitement plus rapide, une meilleure vitesse réseau et une mémoire serveur plus importante et plus rapide. Un hébergement coûteux n'est pas toujours synonyme de meilleur hébergement. De nombreuses mises à niveau sur les services d'hébergement partagé ne vous apportent que plus de stockage, pas plus de puissance CPU.
Je ne recommande pas de changer d'hébergement sans connaître les causes profondes des problèmes de TTFB. Je vous conseille de mettre en place un suivi RUM et d'ajouter des en-têtes Server-Timing.
Lorsque vous mettez à niveau votre hébergement, vous devriez généralement rechercher au moins l'une de ces trois améliorations :
- Obtenir plus de ressources (CPU + RAM) : surtout lorsque le serveur met trop de temps à générer le HTML dynamique.
- DNS plus rapide : de nombreux fournisseurs d'hébergement à petit budget sont réputés pour leurs mauvaises performances DNS.
- Meilleure configuration : recherchez des chiffrements SSL plus rapides, le support de HTTP/3, la compression Brotli et l'accès à la configuration du serveur web (pour désactiver les modules inutiles), pour n'en citer que quelques-uns.
Comment améliorer le TTFB : accélérer la connexion initiale
Un Time to First Byte élevé peut avoir plusieurs causes. Cependant, le DNS, le TCP et le SSL affectent tous les Time to First Bytes. Commençons donc par là. Même si l'optimisation de ces trois éléments ne donne pas forcément les plus grands résultats, leur optimisation optimisera chaque TTFB.
Accélérer le DNS
CONSEIL PageSpeed : le DNS, le TCP et le SSL sont généralement un problème plus important lorsque vous utilisez un hébergeur bon marché ou lorsque vous servez une audience mondiale sans utiliser de CDN. Utilisez le suivi RUM pour consulter votre TTFB mondial et décomposer le TTFB en ses sous-parties.
Utilisez un fournisseur DNS rapide. Tous les fournisseurs DNS ne sont pas aussi rapides les uns que que les autres. Certains fournisseurs DNS (gratuits) sont tout simplement plus lents que d'autres fournisseurs DNS (gratuits). Cloudflare, par exemple, vous propose gratuitement l'un des fournisseurs DNS les plus rapides au monde.
Augmenter le TTL du DNS. Une autre façon est d'augmenter la valeur du Time to Live (TTL). Le TTL est un paramètre qui détermine la durée pendant laquelle la recherche peut être mise en cache. Plus le TTL est élevé, moins le navigateur aura besoin d'effectuer une autre recherche DNS. Il est important de noter que les FAI mettent également le DNS en cache.
Accélérer le TCP
La "partie TCP" du TTFB est la connexion initiale au serveur web. Lors de la connexion, le navigateur et le serveur partagent des informations sur la manière dont les données seront échangées. Vous pouvez accélérer le TCP en vous connectant à un serveur géographiquement proche de votre emplacement et en vous assurant que le serveur dispose de suffisamment de ressources libres. Parfois, passer à un serveur léger comme NGINX peut accélérer la partie TCP du TTFB. Dans de nombreux cas, l'utilisation d'un CDN accélérera la connexion TCP.
Accélérer le SSL/TLS
Une fois la connexion TCP établie, le navigateur et le serveur devront sécuriser la connexion par le biais du chiffrement. Vous pouvez accélérer ce processus en utilisant des protocoles plus rapides, plus récents et plus légers (chiffrements SSL) et en étant géographiquement plus proche de votre serveur web (puisque la négociation TLS nécessite un certain nombre d'allers-retours). L'utilisation d'un CDN améliorera souvent le temps de connexion SSL car les CDN sont souvent très bien configurés et disposent de multiples serveurs dans le monde entier. Le protocole TLS 1.3, en particulier, est conçu pour que la négociation TLS soit aussi courte que possible.
Comment améliorer le TTFB : accélérer le côté serveur
Mise en cache des pages (Page Caching)
Le moyen de loin le plus efficace d'accélérer le Time to First Byte est de servir le HTML depuis le cache du serveur. Il existe plusieurs façons de mettre en œuvre une mise en cache complète des pages. Le moyen le plus efficace est de le faire directement au niveau du serveur web avec, par exemple, le module de mise en cache NGINX ou en utilisant Varnish comme proxy de mise en cache inverse.
Il existe également de nombreux plugins pour différents systèmes CMS qui mettront en cache des pages complètes et de nombreux frameworks SPA comme Next.js ont leur propre mise en œuvre de la mise en cache complète des pages ainsi que différentes stratégies d'invalidation.
Si vous souhaitez mettre en œuvre votre propre mise en cache, l'idée de base est simple. Lorsqu'un client demande une page, vérifiez si elle existe dans le dossier de cache. Si elle n'existe pas, créez la page, écrivez-la dans le cache et affichez la page comme vous le feriez normalement. Lors de toute demande ultérieure de la page, le fichier de cache existera et vous pourrez servir la page directement depuis le cache.
Mise en cache partielle
Avec la mise en cache partielle, l'idée est de mettre en cache les parties de la page ou les ressources fréquemment utilisées, lentes ou coûteuses (comme les appels d'API, les résultats de bases de données) pour une récupération rapide. Cela éliminera les goulots d'étranglement lors de la génération d'une page. Si vous êtes intéressé par ces types d'optimisations, vous devriez rechercher ces concepts : Memory Cache, Object Cache, Database Cache, Object-Relational Mapping (ORM) Cache, Content Fragment Cache et Opcode Cache.
Optimiser le code de l'application
Parfois, la page ne peut pas être servie à partir du cache (partiel) parce que le fichier de cache n'existe pas, que de grandes parties des pages sont dynamiques ou parce que vous rencontrez d'autres problèmes. C'est pourquoi nous devons optimiser le code de l'application. La manière de procéder dépend entièrement de votre application. Elle repose sur la réécriture et l'optimisation des parties lentes de votre code.
Optimiser les requêtes de base de données
La plupart du temps, des requêtes de base de données inefficaces sont la cause profonde d'un Time to First Byte lent. Commencez par journaliser les "requêtes lentes" et les "requêtes n'utilisant pas d'index" sur le disque. Analysez-les, ajoutez des index ou demandez à un expert d'effectuer un réglage de la base de données pour corriger ces problèmes. Voir MongoDB Performance Advisor et MySQL Slow Query Log pour plus de détails.
Réduire la latence du réseau interne
Une mauvaise pratique que je rencontre plus souvent que je ne le souhaiterais est un retard dans le Time to First Byte causé par la lenteur de la communication entre l'application web et le stockage des données. Cela n'arrive généralement que sur les grands sites qui ont externalisé leur stockage de données vers des API cloud.
How to improve the TTFB: speed up the client side
Client side caching
La mise en cache côté client consiste pour le navigateur de l'utilisateur à stocker les ressources auxquelles il a déjà accédé, comme les images et les scripts. Ainsi, lorsque l'utilisateur revient sur votre site web, son navigateur peut récupérer rapidement les ressources mises en cache au lieu de devoir les télécharger à nouveau. Cela peut réduire considérablement le nombre de requêtes adressées au serveur, ce qui peut à son tour réduire le TTFB.
Pour mettre en œuvre la mise en cache côté client, vous pouvez utiliser l'en-tête HTTP Cache-Control. Cet en-tête vous permet de spécifier la durée pendant laquelle le navigateur doit mettre en cache une ressource particulière.
Vous pourriez envisager de mettre complètement en cache le HTML de la page côté client. Cela réduira considérablement le TTFB car aucune requête au serveur n'est nécessaire. L'inconvénient est qu'une fois la page dans le cache du navigateur, toute mise à jour de la version en direct de la page ne sera pas vue par l'utilisateur tant que le cache de la page n'aura pas expiré.
Service Workers
Les service workers sont des scripts qui s'exécutent en arrière-plan du navigateur d'un utilisateur et peuvent intercepter les requêtes réseau effectuées par le navigateur. Cela signifie que les service workers peuvent mettre en cache des ressources telles que le HTML, les images, les scripts et les feuilles de style, de sorte que lorsque l'utilisateur revient sur votre site web, son navigateur peut récupérer rapidement les ressources mises en cache au lieu de devoir les télécharger à nouveau.
Page Prefetching
Si vous ne souhaitez pas utiliser l'API Speculation Rules en raison de son support limité par les navigateurs, vous pourriez utiliser un petit script appelé quicklink. Celui-ci va précharger tous les liens se trouvant dans la fenêtre d'affichage visible et pratiquement éliminer le Time To First Byte pour ces liens.
L'inconvénient de quicklink est qu'il nécessite plus de ressources du navigateur, mais pour l'instant, il surpasse l'API Speculation Rules en termes de couverture des navigateurs.
Comment améliorer le TTFB : utiliser un CDN
Un Content Delivery Network ou CDN utilise un réseau distribué de serveurs pour livrer les ressources aux utilisateurs. Ces serveurs sont généralement géographiquement plus proches des utilisateurs finaux et hautement optimisés pour la vitesse. Si vous utilisez Cloudflare, consultez notre guide sur la façon de configurer Cloudflare pour des performances Core Web Vitals optimales.
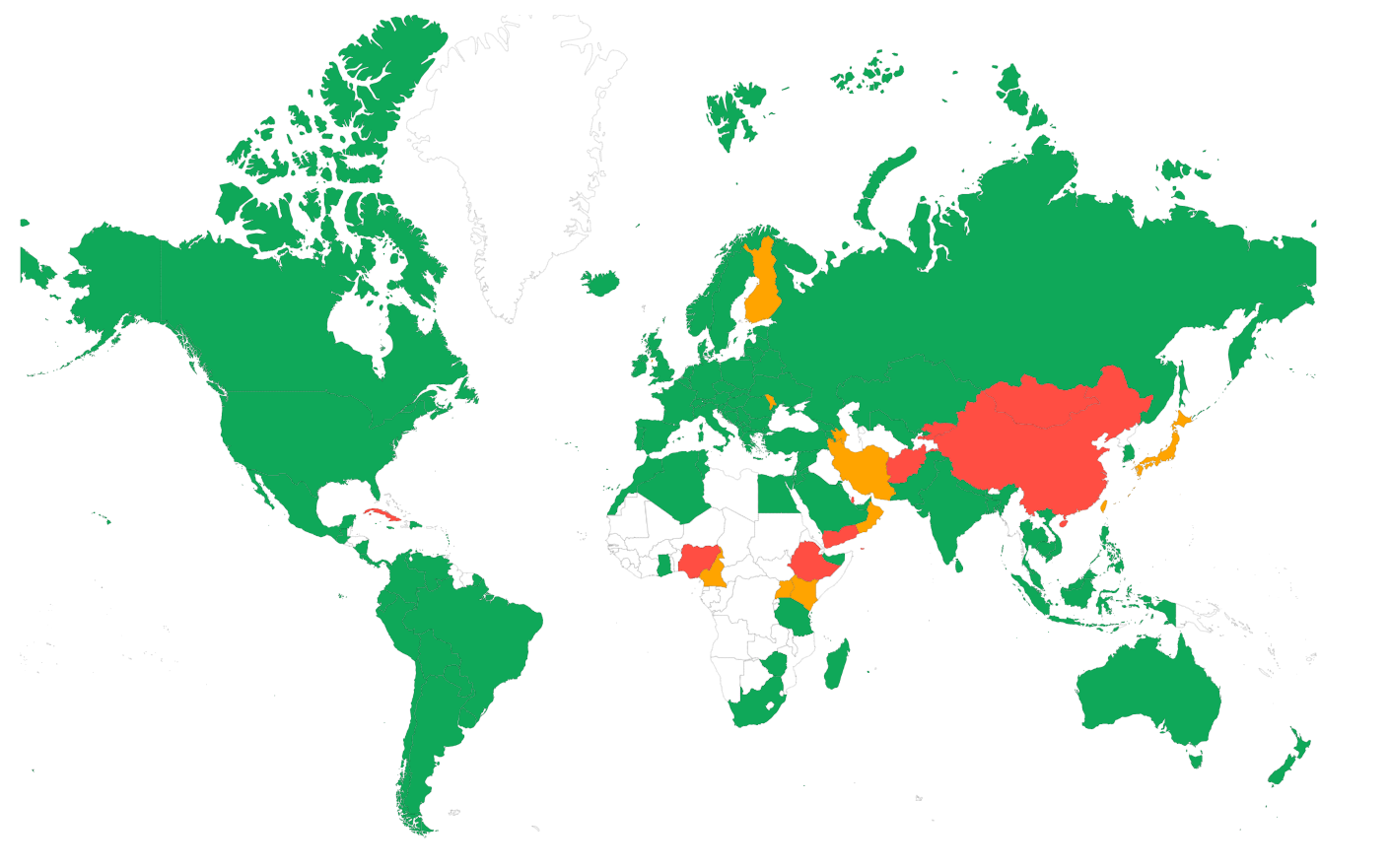
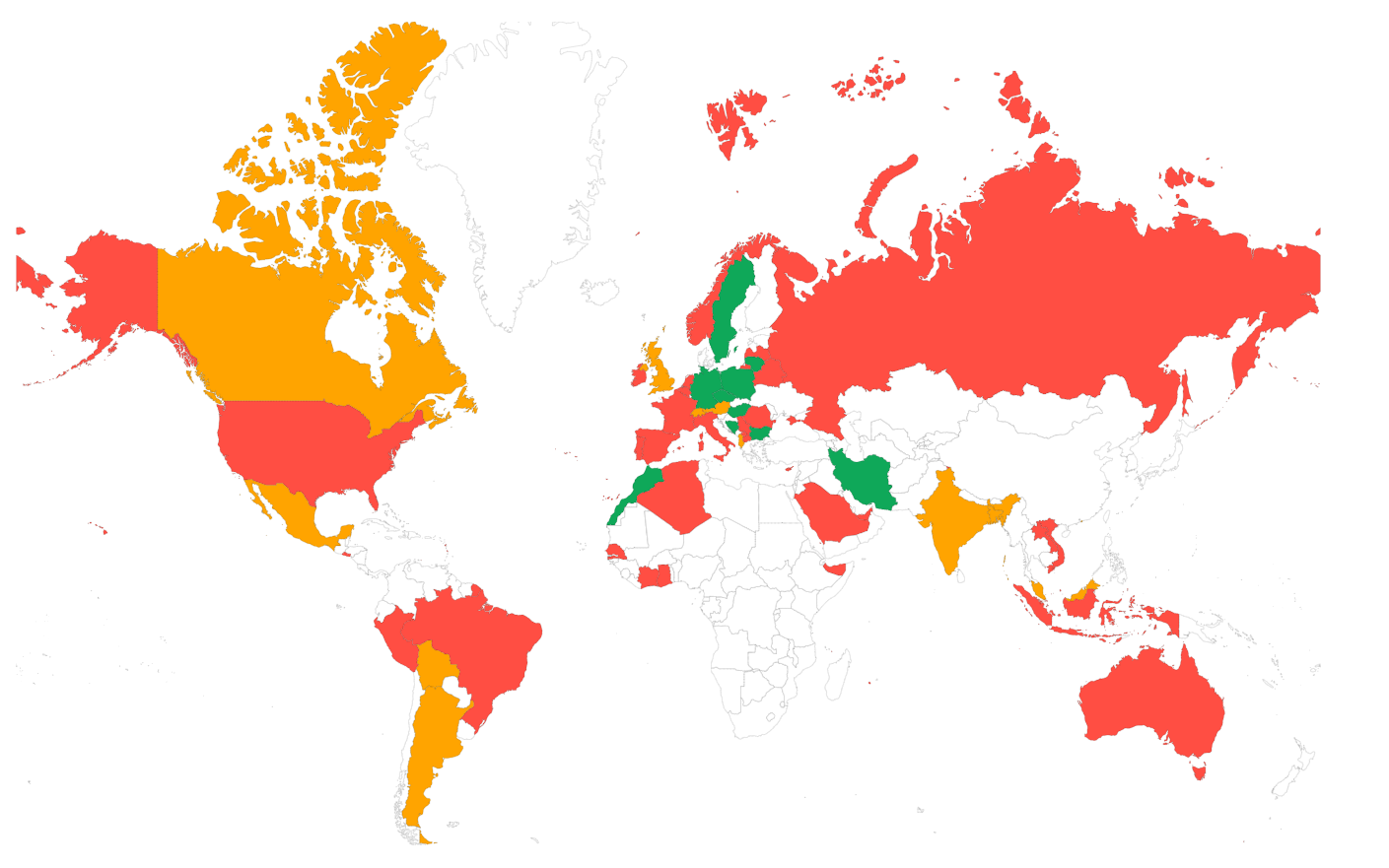
Un CDN peut aider à améliorer 5 des 6 parties du Time to First Byte :
- Temps de redirection : la plupart des CDN peuvent mettre en cache les redirections à la périphérie ou utiliser des edge workers pour gérer les redirections sans avoir besoin de se connecter au serveur d'origine.
- Temps de recherche DNS : la plupart des CDN proposent des serveurs DNS extrêmement rapides qui surpasseront probablement vos serveurs DNS actuels.
- Temps de connexion TCP et de handshake SSL : la plupart des CDN sont extrêmement bien configurés et ces configurations, associées à la proximité plus étroite des utilisateurs finaux, accéléreront le temps de connexion et de handshake.
- Réponse du serveur : les CDN peuvent accélérer le temps de réponse du serveur de plusieurs manières. La première consiste à mettre en cache la réponse du serveur à la périphérie (mise en cache complète de la page en bordure), mais aussi à proposer une excellente compression (Brotli) et les protocoles les plus récents (HTTP/3).
Comment améliorer le TTFB : éviter les redirections
Le temps de redirection s'ajoute au Time To First Byte. Par conséquent, en règle générale, évitez autant que possible les redirections. Des redirections peuvent se produire lorsqu'une ressource n'est plus disponible à un endroit mais a été déplacée vers un autre. Le serveur répondra avec un en-tête de réponse de redirection et le navigateur essaiera ce nouvel emplacement.
Redirections de même origine (Same origin). Les redirections de même origine proviennent de liens sur votre propre site web. Vous devriez avoir un contrôle total sur ces liens et vous devriez donner la priorité à leur correction lorsque vous travaillez sur le Time to First Byte. Il existe de nombreux outils qui vous permettront de vérifier l'ensemble de votre site web pour les redirections.
Redirections d'origines croisées (Cross-origin). Les redirections d'origines croisées proviennent de liens sur d'autres sites web. Vous avez très peu de contrôle sur celles-ci.
Redirections multiples. Les redirections multiples ou chaînes de redirections se produisent lorsqu'une seule redirection ne renvoie pas à l'emplacement final de la ressource. Ces types de redirections pèsent plus lourdement sur le Time to First Byte et doivent être évités à tout prix. Là encore, utilisez un outil pour trouver ces types de redirections et les corriger.
Redirections HTTP vers HTTPS. Une façon de contourner ce problème est d'utiliser l'en-tête Strict-Transport-Security (HSTS), qui imposera le HTTPS lors de la première visite à une origine, puis dira au navigateur d'accéder immédiatement à l'origine via le protocole HTTPS lors des visites futures.
Lorsqu'un utilisateur demande une page web, le serveur peut répondre par une redirection vers une autre page. Cette redirection peut ajouter du temps supplémentaire au TTFB car le navigateur doit effectuer une requête supplémentaire vers la nouvelle page.
Il existe plusieurs façons d'éviter les redirections ou de minimiser leur impact :
- Mettez à jour vos liens internes. Chaque fois que vous changez l'emplacement d'une page, mettez à jour vos liens internes vers cette page pour vous assurer qu'il ne reste aucune référence à l'ancien emplacement de la page.
- Gérez les redirections au niveau du serveur.
- Utilisez des URL relatives : lorsque vous créez des liens vers des pages de votre propre site web, utilisez des URL relatives au lieu d'URL absolues. Cela aidera à prévenir les redirections inutiles.
- Utilisez des URL canoniques : si vous avez plusieurs pages avec un contenu similaire, utilisez une URL canonique pour indiquer la version préférée de la page. Cela aidera à prévenir le contenu dupliqué et les redirections inutiles.
- Utilisez des redirections 301 : si vous devez utiliser une redirection, utilisez une redirection 301 au lieu d'une redirection 302. Une redirection 301 est une redirection permanente, tandis qu'une redirection 302 est une redirection temporaire. L'utilisation d'une redirection 301 aidera à prévenir les redirections inutiles.
Optimisez la priorisation des ressources parallèlement au TTFB
Réduire le TTFB n'est qu'une partie de l'histoire de la performance de chargement. Une fois que le premier octet arrive, le navigateur doit savoir quelles ressources prioriser. Lisez notre guide sur la priorisation des ressources pour apprendre comment les suggestions fetchpriority, preload, et preconnect fonctionnent de concert avec un TTFB rapide pour offrir les chargements de page les plus rapides possibles. En outre, envisagez d'auto-héberger vos Google Fonts pour éliminer les recherches DNS tierces et les temps de connexion qui s'ajoutent au TTFB perçu par vos utilisateurs.
Ce que montrent les données réelles sur le TTFB
Les données suivantes proviennent du Real User Monitoring de CoreDash et du Web Almanac 2025.
La variation géographique est énorme
Le TTFB varie considérablement en fonction de la distance physique entre l'utilisateur et le serveur. Les données CoreDash de corewebvitals.io (hébergé en Europe) l'illustrent clairement :
| Pays | TTFB p75 | % Bon |
|---|---|---|
| République tchèque | 62ms | 98,8% |
| Pays-Bas | 106ms | 97,0% |
| Allemagne | 138ms | 98,5% |
| Royaume-Uni | 169ms | 97,7% |
| États-Unis | 284ms | 92,7% |
| Inde | 404ms | 88,2% |
| Chine | 1 468ms | 26,6% |
Les utilisateurs européens proches du serveur voient un TTFB inférieur à 170 ms, tandis que les utilisateurs en Inde connaissent un TTFB 3 fois plus élevé et les utilisateurs en Chine voient un TTFB presque 10 fois plus élevé (1 468 ms) en raison du Grand Firewall et de la distance physique pure. Ces données démontrent pourquoi un CDN avec des emplacements périphériques mondiaux est essentiel pour les audiences internationales.
Le pré-rendu par Speculation Rules offre un TTFB de 0 ms
Les données CoreDash sur le type de navigation confirment que les pages pré-rendues via les Speculation Rules atteignent un TTFB p75 de 0 milliseconde. Les navigations standard mesurent 131 ms, les rechargements 82 ms (bénéficiant de connexions déjà établies), et les navigations retour-avant sont les plus lentes avec 244 ms. Cela fait des Speculation Rules la technique la plus efficace pour éliminer le TTFB lors des chargements de pages ultérieurs.
Le TTFB mobile est 2,5 fois plus élevé que celui de l'ordinateur de bureau
Sur corewebvitals.io, les utilisateurs mobiles connaissent un TTFB p75 de 316 ms, contre 124 ms sur ordinateur. Cet écart de 2,5x est causé par la latence du réseau mobile, et non par des différences de serveur. Seuls 88,5 % des chargements de pages mobiles atteignent une évaluation TTFB "bonne", contre 96,1 % sur ordinateur. Lors de l'optimisation du TTFB, testez toujours sur de réels réseaux mobiles.
Les nouveaux visiteurs et les visiteurs récurrents voient un TTFB similaire
Sur ce site, les nouveaux visiteurs voient un TTFB p75 de 127 ms tandis que les visiteurs récurrents voient 138 ms. Cette similitude suggère qu'une mise en cache cohérente côté serveur (plutôt que les avantages du cache côté client) est le principal facteur de performance du TTFB. Sur les sites sans mise en cache côté serveur, l'écart entre les nouveaux visiteurs et les visiteurs récurrents peut être beaucoup plus important.
Le TTFB mondial stagne depuis 5 ans
Selon le Web Almanac 2025, seulement 44 % des pages mobiles obtiennent un "bon" score TTFB à l'échelle mondiale. Ce chiffre a à peine changé par rapport aux 41 % de 2021, ce qui fait du TTFB la métrique de performance la plus stagnante sur le web. Pendant ce temps, le LCP s'est amélioré de 44 % à 59 % et l'INP de 55 % à 74 % sur la même période. Les sites ayant un mauvais LCP passent en moyenne 2,27 secondes rien que sur le TTFB, soit presque la totalité du seuil de 2,5 secondes du LCP.
Foire aux questions sur le TTFB
Qu'est-ce qu'un bon TTFB ?
Un bon Time to First Byte est de 800 millisecondes ou moins au 75e percentile. Cela signifie que 75 % de vos utilisateurs devraient recevoir le premier octet de la réponse dans les 800 ms. Un TTFB compris entre 800 ms et 1 800 ms nécessite une amélioration, et un TTFB supérieur à 1 800 ms est considéré comme médiocre. Notez que ces seuils s'appliquent au TTFB de navigation complet, incluant le DNS, le TCP, le TLS et le temps de traitement du serveur.
Le TTFB est-il un Core Web Vital ?
Non, le TTFB n'est pas un Core Web Vital. Les trois Core Web Vitals sont le Largest Contentful Paint (LCP), l'Interaction to Next Paint (INP) et le Cumulative Layout Shift (CLS). Le TTFB est classé comme une métrique de diagnostic. Il n'est pas directement utilisé dans les signaux de classement de l'expérience utilisateur de Google, mais il a un impact indirect majeur car un TTFB lent augmente directement le LCP et le FCP. L'optimisation du TTFB est souvent le moyen le plus rapide d'améliorer vos scores Core Web Vitals.
Comment un CDN réduit-il le TTFB ?
Un CDN (Content Delivery Network) réduit le TTFB de plusieurs manières. Premièrement, il place des serveurs géographiquement plus proches de vos utilisateurs, ce qui réduit la latence du réseau pour les recherches DNS, les connexions TCP et les handshakes TLS. Deuxièmement, un CDN peut mettre en cache vos pages sur des serveurs périphériques afin que la réponse puisse être servie sans se connecter du tout à votre serveur d'origine. Troisièmement, les CDN proposent généralement des configurations hautement optimisées incluant HTTP/3, la compression Brotli et une négociation TLS rapide. Les données de CoreDash montrent que les utilisateurs proches du serveur (République tchèque : 62 ms) connaissent un TTFB considérablement plus bas que les utilisateurs éloignés (Inde : 404 ms, Chine : 1 468 ms).
Quelle est la différence entre le TTFB et le temps de réponse du serveur ?
Le temps de réponse du serveur mesure uniquement le temps que le serveur passe à traiter la requête et à générer la réponse. Le TTFB inclut le temps de réponse du serveur plus tout l'overhead réseau : résolution DNS, connexion TCP, handshake TLS et le temps de transit réseau pour la requête et le premier octet de la réponse. Un site peut avoir un temps de réponse serveur rapide (mesuré via l'API Server-Timing) mais avoir tout de même un TTFB lent si l'utilisateur est loin du serveur ou sur un réseau lent. Lors du débogage des problèmes de TTFB, il est important de décomposer la métrique en ses sous-parties pour déterminer si le problème se situe côté serveur ou côté réseau.
Pourquoi mon TTFB est-il élevé pour certains pays ?
Le TTFB varie selon les pays en raison de la distance physique, de la qualité de l'infrastructure réseau et du routage Internet. Chaque sous-partie du TTFB (DNS, TCP, TLS, réponse du serveur) est affectée par le temps de trajet aller-retour entre l'utilisateur et le serveur. Un utilisateur en Inde se connectant à un serveur en Allemagne connaîtra plusieurs allers-retours sur des milliers de kilomètres, chacun ajoutant de la latence. Les pays dont l'infrastructure Internet est moins développée ou dotés de pare-feu restrictifs (comme la Chine) connaissent des TTFB encore plus élevés. La solution consiste à utiliser un CDN qui met en cache votre contenu sur des serveurs périphériques proches de vos utilisateurs, ou à déployer votre application dans plusieurs régions.
Guides connexes : sous-parties du TTFB
Chaque sous-partie du Time to First Byte possède ses propres stratégies d'optimisation :
- <b>Identifier et résoudre les problèmes de TTFB</b> : un guide de diagnostic étape par étape pour trouver la cause profonde d'un TTFB lent à l'aide de DevTools, Server-Timing et des données RUM.
- <b>Réduire la Waiting Duration</b> : comment minimiser le temps de redirection et les délais de traitement du serveur qui s'ajoutent à votre TTFB.
- <b>Réduire la Cache Duration</b> : stratégies pour la mise en cache du navigateur, les service workers et le cache retour-avant (bfcache) afin d'éliminer le TTFB pour les visiteurs récurrents.
- <b>Minimiser la DNS Duration</b> : comment accélérer la résolution DNS avec des fournisseurs DNS plus rapides, des valeurs TTL augmentées et des suggestions de ressources
dns-prefetch. - <b>Optimiser la Connection Duration (TCP + TLS)</b> : réduction du temps de handshake TCP et TLS avec HTTP/3, TLS 1.3, la reprise de session et les suggestions
preconnect.
J'ai construit CoreDash pour mes propres audits.
Moins de 1KB. Hosting EU. Sans bannière cookies. Et maintenant MCP intégré.
Essayez CoreDash gratuitement
