Qué es el Time To First Byte (TTFB) y cómo mejorarlo
Qué es el Time to First Byte, por qué es importante para tus Core Web Vitals y cómo optimizarlo

El Time to First Byte (TTFB) mide el tiempo en milisegundos entre el momento en que el navegador solicita una página y el momento en que recibe el primer byte de la respuesta del servidor. Un buen TTFB es de 800 milisegundos o menos en el percentil 75. El TTFB no es un Core Web Vital, pero es una métrica de diagnóstico fundamental porque afecta directamente tanto al Largest Contentful Paint (LCP) como al First Contentful Paint (FCP).
Table of Contents!
- Qué es el Time to First Byte
- El TTFB no es un Core Web Vital
- Por qué es importante el Time to First Byte
- ¿Qué es una buena puntuación TTFB?
- Impacto en el mundo real: el caso de estudio de T-Mobile
- El TTFB desde la solicitud hasta la respuesta
- Medición del TTFB con Server-Timing
- Acelera el TTFB con 103 Early Hints
- Elimina el TTFB con la API Speculation Rules
- ¿Cómo afecta el alojamiento (hosting) al Time to First Byte?
- Cómo mejorar el TTFB: acelera la conexión inicial
- Cómo mejorar el TTFB: acelera el lado del servidor
- Cómo mejorar el TTFB: acelera el lado del cliente
- Cómo mejorar el TTFB: usa un CDN
- Cómo mejorar el TTFB: evita las redirecciones
- Optimiza la priorización de recursos junto con el TTFB
- Lo que muestran los datos de TTFB en el mundo real
- Preguntas frecuentes sobre el TTFB
- Guías relacionadas: Subpartes del TTFB
Qué es el Time to First Byte
El Time to First Byte (TTFB) indica cuánto tiempo ha transcurrido en milisegundos entre el inicio de la solicitud y la recepción de la primera respuesta (byte) de una página web. Por lo tanto, el TTFB también se conoce como tiempo de espera. El TTFB es una forma de medir la capacidad de respuesta de un servidor web y la ruta de red entre el usuario y ese servidor. El TTFB es una métrica fundamental; esto significa que el tiempo añadido al TTFB también se añadirá al Largest Contentful Paint y al First Contentful Paint. Cada milisegundo ahorrado en el TTFB es un milisegundo ahorrado en ambas métricas de renderizado.

El TTFB no es un Core Web Vital
Es importante dejar esto claro: el TTFB no es uno de los tres Core Web Vitals. Los Core Web Vitals consisten en Largest Contentful Paint (LCP), Interaction to Next Paint (INP) y Cumulative Layout Shift (CLS). Google no utiliza el TTFB directamente en sus señales de clasificación de la experiencia de la página.
Sin embargo, el TTFB está clasificado como una métrica de diagnóstico. Te ayuda a entender por qué tu LCP o FCP podría ser lento. Según el Web Almanac 2025, los sitios con un LCP deficiente pasan una media de 2,27 segundos solo en el TTFB, lo que agota casi por completo el umbral de 2,5 segundos del LCP antes incluso de que el navegador comience a renderizar la página. Arreglar el TTFB es, por lo tanto, una de las acciones con mayor impacto que puedes realizar para tus puntuaciones globales de Core Web Vitals.
Por qué es importante el Time to First Byte
El Time to First Byte no es un Core Web Vital y es muy posible aprobar los Core Web Vitals y suspender en la métrica TTFB. Eso no significa que el TTFB no sea importante. El TTFB es una métrica extremadamente importante de optimizar y corregir el TTFB mejorará en gran medida la velocidad de la página y la experiencia del usuario.
El impacto del TTFB en los visitantes
El Time to First Byte precede a todas las demás métricas de renderizado. Mientras el navegador espera el Time to First Byte, no puede hacer nada y simplemente mostrará una pantalla en blanco. Esto significa que cualquier aumento en el Time to First Byte resultará en un tiempo extra de "pantalla en blanco" y cualquier disminución en el Time to First Byte se traducirá en menos tiempo de "pantalla en blanco".
Para conseguir esa sensación de carga instantánea de las páginas, el Time to First Byte tiene que ser lo más rápido posible.
¿Por qué el TTFB no es un Core Web Vital? El TTFB no tiene en cuenta el renderizado: un TTFB bajo no significa necesariamente una buena experiencia de usuario porque no considera el tiempo que tarda el navegador en renderizar la página web. Incluso si todos los bytes se descargan rápidamente, la página web podría tardar mucho en mostrarse si el navegador necesita procesar mucho JavaScript o renderizar diseños complejos.
¿Qué es una buena puntuación TTFB?

Se recomienda que tu servidor responda a las solicitudes de navegación lo suficientemente rápido como para que el percentil 75 de los usuarios experimente un FCP dentro del umbral "bueno". Como guía general, la mayoría de los sitios deberían esforzarse por tener un TTFB de 0,8 segundos o menos.
- Un TTFB inferior a 800 milisegundos se considera bueno.
- Un TTFB entre 800 y 1800 milisegundos necesita mejoras.
- Un TTFB superior a 1800 milisegundos se considera deficiente y debe mejorarse inmediatamente.
Impacto en el mundo real: el caso de estudio de T-Mobile
T-Mobile invirtió fuertemente en reducir su Time to First Byte como parte de una iniciativa más amplia de optimización del rendimiento. Los resultados fueron sorprendentes: un aumento del 60 % en las conversiones de visita a pedido. Al pasar a páginas renderizadas en el borde (edge-rendered) y a un agresivo almacenamiento en caché del lado del servidor, T-Mobile redujo drásticamente el tiempo que los usuarios pasaban esperando el primer byte, lo que se tradujo en un LCP más rápido, un FCP más rápido y una experiencia de usuario mensurablemente mejor. Este caso de estudio demuestra que la optimización del TTFB no es solo un ejercicio técnico; afecta directamente a los resultados comerciales.
El TTFB desde la solicitud hasta la respuesta
Del navegador al servidor: La solicitud
El tiempo de solicitud del navegador es el tiempo transcurrido desde el momento en que el navegador de un usuario envía una solicitud HTTP hasta que esa solicitud llega al servidor que aloja el sitio web. El TTFB de esta parte escapa en gran medida al control directo del sitio web y depende en gran medida de:
- La velocidad de internet del usuario.
- La calidad de su infraestructura de red.
- La distancia física entre el usuario y el servidor.
En esta etapa, la búsqueda de DNS, el tiempo de inicio del navegador, las búsquedas en la caché del navegador y la negociación de la conexión al servidor (TCP y TLS) consumen un poco de tiempo.
En el servidor: Procesamiento
Una vez que la solicitud ha llegado al servidor, el servidor tiene que procesar la solicitud y generar la respuesta. El tiempo que necesita el servidor para este paso se llama tiempo de procesamiento del servidor. Este tiempo depende de múltiples factores, como la complejidad del sitio web, la eficiencia del código del lado del servidor y los recursos disponibles en el servidor (CPU, RAM). Esta es la parte del TTFB sobre la que tienes más control.
Del servidor al navegador: La respuesta
Una vez que el servidor ha generado la respuesta, tiene que enviarla de vuelta al navegador del usuario. El tiempo que tarda el primer byte de la respuesta en llegar al navegador del usuario se llama tiempo de respuesta. Al igual que el tiempo de solicitud, esta parte del TTFB depende de la conexión a Internet del usuario y de la distancia física entre el usuario y el servidor.
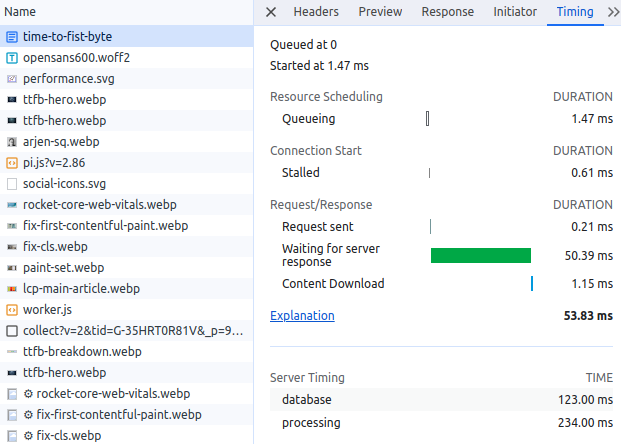
Medición del TTFB con Server-Timing
Para medir el tiempo de procesamiento en el lado del servidor, puedes utilizar la API Server-Timing. Esta API permite a los servidores enviar información sobre su rendimiento al navegador, que luego puede verse en las Herramientas para desarrolladores (DevTools) del navegador.
La API Server-Timing funciona enviando un encabezado de respuesta HTTP desde el servidor al navegador. Este encabezado puede contener varias métricas separadas por comas. Cada entrada consta de:
- Un nombre corto para la métrica (como
databaseyprocessing) - Una duración en milisegundos (expresada como
dur=123) - Una descripción opcional (expresada como
desc="Mi Descripción")
Server-Timing: database;dur=123;desc="DB Query", processing;dur=234;desc="Template Render", cache;dur=0;desc="Cache HIT"
Lectura de Server-Timing en Chrome DevTools
Chrome DevTools muestra las entradas de Server-Timing directamente en el panel Network (Red). Abre DevTools, selecciona la solicitud del documento en la pestaña Network, desplázate hacia abajo hasta la sección "Server Timing" en la pestaña Timing (Tiempos). Cada métrica que envíes a través del encabezado Server-Timing aparecerá con su nombre, descripción y duración. Esto hace que sea sencillo identificar si el cuello de botella es la base de datos, el renderizado de la plantilla o la capa de almacenamiento en caché.
También puedes leer el encabezado Server-Timing mediante programación y enviar estos tiempos a tu herramienta RUM favorita como CoreDash para un seguimiento a largo plazo y la creación de alertas.
Acelera el TTFB con 103 Early Hints
103 Early Hints es un código de estado HTTP que permite al servidor enviar encabezados de respuesta preliminares al navegador antes de que la respuesta final esté lista. Mientras el servidor sigue procesando la solicitud (consultando la base de datos, renderizando la plantilla), el navegador ya puede empezar a cargar recursos críticos como hojas de estilo, fuentes y la imagen del LCP.
Cómo funcionan los 103 Early Hints
En un flujo de solicitud tradicional, el navegador permanece inactivo durante todo el tiempo de procesamiento del servidor. Con los 103 Early Hints, el servidor envía una respuesta parcial inmediatamente después de recibir la solicitud. Esta respuesta parcial contiene encabezados Link que indican al navegador qué recursos pre-cargar (preload) o a cuáles pre-conectarse (preconnect). El navegador actúa sobre estas pistas (hints) mientras espera la respuesta 200 completa.
Esto convierte efectivamente el tiempo de espera muerto en tiempo de carga productivo. Aunque los 103 Early Hints no reducen el TTFB del documento en sí, reducen el impacto percibido del TTFB en métricas posteriores como LCP y FCP al darle al navegador una ventaja en el descubrimiento de recursos.
Ejemplo de configuración del servidor para 103 Early Hints
Muchos CDN y servidores web ahora soportan los 103 Early Hints. Aquí hay un ejemplo usando Cloudflare, que genera automáticamente los 103 Early Hints a partir de los encabezados Link y las etiquetas preload/preconnect que se encuentran en tu HTML:
HTTP/1.1 103 Early Hints Link: </style.css>; rel=preload; as=style Link: </static/img/hero.webp>; rel=preload; as=image Link: <https://fonts.googleapis.com>; rel=preconnect HTTP/1.1 200 OK Content-Type: text/html ...
Para Nginx, puedes configurar los Early Hints añadiendo encabezados Link a tu respuesta y habilitando push sobre HTTP/2 o HTTP/3. Apache soporta 103 Early Hints a través de la directiva H2EarlyHints. Consulta nuestra guía detallada sobre cómo implementar los 103 Early Hints para obtener instrucciones paso a paso.
Elimina el TTFB con la API Speculation Rules
La API Speculation Rules está diseñada para mejorar el rendimiento de las navegaciones futuras. Una vez que un visitante ha aterrizado en tu página, puedes usar las Speculation Rules para indicarle al navegador que obtenga (fetch, con la directiva prefetch) o incluso que renderice completamente (con la directiva prerender) las páginas que es más probable que el visitante visite a continuación.
Cómo las Speculation Rules eliminan el TTFB
Cuando una página es pre-renderizada (prerendered), el navegador la carga y renderiza completamente en una pestaña oculta. Cuando el usuario hace clic en el enlace, la página pre-renderizada se intercambia al instante. El resultado: un TTFB medido de 0 milisegundos. Esto no es un número teórico. Los datos RUM de CoreDash procedentes de corewebvitals.io confirman que las navegaciones pre-renderizadas a través de las Speculation Rules muestran un TTFB en el percentil 75 de 0 ms.
El Prefetching es una alternativa más ligera. En lugar de renderizar completamente la página, el navegador solo obtiene el documento HTML y lo guarda en caché. Esto elimina la parte de red del TTFB al mismo tiempo que sigue requiriendo que el navegador analice y renderice el documento durante la navegación.
Sintaxis JSON de las Speculation Rules
Las Speculation Rules se definen utilizando un bloque <script type="speculationrules"> que contiene JSON. Aquí hay un ejemplo que pre-renderiza todos los enlaces de navegación de tu barra de menú con una impaciencia (eagerness) "moderada" (activada al pasar el ratón por encima o al presionar con el puntero):
<script type="speculationrules">
{"prerender":
[{
"source": "document",
"where": {"selector_matches": "nav a"},
"eagerness": "moderate"
}]}
</script>
También puedes usar un enfoque basado en listas para URL específicas:
<script type="speculationrules">
{"prefetch":
[{
"source": "list",
"urls": ["/core-web-vitals/", "/pagespeed/103-early-hints"]
}]}
</script>
La compatibilidad de los navegadores con las Speculation Rules está creciendo. Chrome 121+ soporta la API completa, incluidas las reglas de documentos. Para los navegadores que aún no soportan las Speculation Rules, podrías utilizar un script ligero como quicklink como alternativa. Utiliza nuestro Generador de Speculation Rules para crear la configuración adecuada para tu sitio.
¿Cómo afecta el alojamiento (hosting) al Time to First Byte?
El alojamiento afecta al Time to First Byte de múltiples maneras. Al invertir en un mejor alojamiento, generalmente es posible mejorar inmediatamente el Time to First Byte sin cambiar nada más. Especialmente cuando se cambia de un alojamiento compartido de bajo presupuesto a servidores virtuales correctamente configurados y administrados, el TTFB podría mejorar drásticamente.
CONSEJO sobre el alojamiento: un mejor alojamiento implica un procesamiento más rápido, una mejor velocidad de red y más memoria de servidor, además de ser más rápida. Un alojamiento caro no siempre es sinónimo de un mejor alojamiento. Muchas mejoras en los servicios de alojamiento compartido solo te proporcionan más almacenamiento, no más potencia de CPU.
No recomiendo cambiar de alojamiento sin conocer las causas fundamentales de los problemas del TTFB. Te aconsejo que configures el seguimiento RUM y añadas encabezados Server-Timing.
Cuando actualices tu alojamiento, generalmente deberías buscar al menos una de estas tres mejoras:
- Obtener más recursos (CPU + RAM): especialmente cuando el servidor tarda demasiado en generar el HTML dinámico.
- DNS más rápido: muchos proveedores de alojamiento de bajo presupuesto son notorios por su deficiente rendimiento de DNS.
- Mejor configuración: busca cifrados SSL más rápidos, compatibilidad con HTTP/3, compresión Brotli y acceso a la configuración del servidor web (para deshabilitar módulos innecesarios), por nombrar algunos.
Cómo mejorar el TTFB: acelera la conexión inicial
Un alto Time to First Byte puede tener múltiples causas. Sin embargo, el DNS, el TCP y el SSL afectan a todos los Time to First Byte. Así que empecemos por ahí. Aunque la optimización de estos tres factores no produzca los resultados más grandes, su optimización mejorará cada TTFB individual.
Acelerar el DNS
CONSEJO de PageSpeed: el DNS, el TCP y el SSL suelen ser un problema mayor cuando utilizas un alojamiento barato o cuando atiendes a una audiencia global sin utilizar un CDN. Usa el seguimiento RUM para ver tu TTFB global y desglosar el TTFB en sus subpartes.
Usa un proveedor de DNS rápido. No todos los proveedores de DNS son igual de rápidos. Algunos proveedores de DNS (gratuitos) son simplemente más lentos que otros proveedores de DNS (gratuitos). Cloudflare, por ejemplo, te proporcionará uno de los proveedores de DNS más rápidos del mundo de forma gratuita.
Aumentar el TTL del DNS. Otra forma es aumentar el valor del Tiempo de Vida (TTL, Time to Live). El TTL es un ajuste que determina cuánto tiempo se puede almacenar en caché la búsqueda. Cuanto mayor sea el TTL, menos probable será que el navegador necesite realizar otra búsqueda de DNS. Es importante tener en cuenta que los ISP también almacenan en caché los DNS.
Acelerar el TCP
La "parte TCP" del TTFB es la conexión inicial al servidor web. Al conectarse, el navegador y el servidor comparten información sobre cómo se intercambiarán los datos. Puedes acelerar el TCP conectándote a un servidor que esté geográficamente cerca de tu ubicación y asegurándote de que el servidor tenga suficientes recursos libres. A veces, cambiar a un servidor ligero como NGINX puede acelerar la parte TCP del TTFB. En muchos casos, el uso de un CDN acelerará la conexión TCP.
Acelerar el SSL/TLS
Una vez que se ha establecido la conexión TCP, el navegador y el servidor tendrán que asegurar la conexión mediante encriptación. Puedes acelerar esto usando protocolos más rápidos, más nuevos y más ligeros (cifrados SSL) y estando geográficamente más cerca de tu servidor web (ya que la negociación TLS requiere bastantes viajes de ida y vuelta). El uso de un CDN a menudo mejorará el tiempo de conexión SSL, ya que los CDN suelen estar muy bien configurados y tienen múltiples servidores por todo el mundo. TLS 1.3 en particular está diseñado para mantener la negociación TLS lo más corta posible.
Cómo mejorar el TTFB: acelera el lado del servidor
Caché de páginas (Page Caching)
De lejos, la forma más eficiente de acelerar el Time to First Byte es servir el HTML desde la caché del servidor. Hay varias formas de implementar el almacenamiento en caché de página completa. La forma más efectiva es haciéndolo directamente a nivel del servidor web con, por ejemplo, el módulo de almacenamiento en caché de NGINX o usando Varnish como un proxy inverso de caché.
También hay una gran cantidad de plugins para diferentes sistemas CMS que almacenarán en caché páginas completas y muchos frameworks SPA como Next.js tienen su propia implementación del almacenamiento en caché de página completa junto con diferentes estrategias de invalidación.
Si deseas implementar tu propia caché, la idea básica es simple. Cuando un cliente solicita una página, comprueba si existe en la carpeta de caché. Si no existe, crea la página, escríbela en la caché y muestra la página como lo harías normalmente. En cualquier solicitud posterior de la página, el archivo de caché existirá y podrás servir la página directamente desde la caché.
Caché parcial
Con el almacenamiento en caché parcial, la idea es almacenar en caché las partes de la página o los recursos de uso frecuente, lentos o costosos (como llamadas a API, resultados de bases de datos) para una recuperación rápida. Esto eliminará los cuellos de botella al generar una página. Si estás interesado en este tipo de optimizaciones, deberías investigar estos conceptos: Memory Cache, Object Cache, Database Cache, Object-Relational Mapping (ORM) Cache, Content Fragment Cache y Opcode Cache.
Optimizar el código de la aplicación
A veces, la página no se puede servir desde la caché (parcial) porque el archivo de caché no existe, grandes partes de las páginas son dinámicas o porque te encuentras con otros problemas. Es por eso que necesitamos optimizar el código de la aplicación. La forma de hacerlo depende por completo de tu aplicación. Se basa en reescribir y optimizar las partes lentas de tu código.
Optimizar las consultas a la base de datos
La mayoría de las veces, las consultas ineficaces a la base de datos son la causa principal de un Time to First Byte lento. Empieza registrando las "consultas lentas" y las "consultas que no usan índices" en el disco. Analízalas, añade índices o pide a un experto que realice un ajuste de la base de datos (database tuning) para solucionar estos problemas. Consulta el Asesor de rendimiento de MongoDB y el Registro de consultas lentas de MySQL para obtener más detalles.
Reducir la latencia de la red interna
Una mala práctica con la que me encuentro más veces de las que me gustaría es un retraso en el Time to First Byte causado por la lentitud en la comunicación entre la aplicación web y el almacenamiento de datos. Esto suele ocurrir solo con sitios grandes que han subcontratado su almacenamiento de datos a API en la nube.
Cómo mejorar el TTFB: acelera el lado del cliente
Caché del lado del cliente
El almacenamiento en caché del lado del cliente consiste en que el navegador del usuario almacena los recursos a los que ya ha accedido, como imágenes y scripts. Por lo tanto, cuando el usuario regresa a tu sitio web, su navegador puede recuperar rápidamente los recursos almacenados en caché en lugar de tener que descargarlos de nuevo. Esto puede reducir significativamente la cantidad de solicitudes realizadas al servidor, lo que a su vez puede reducir el TTFB.
Para implementar el almacenamiento en caché del lado del cliente, puedes utilizar el encabezado HTTP Cache-Control. Este encabezado te permite especificar cuánto tiempo el navegador debe almacenar en caché un recurso en particular.
Podrías considerar almacenar en caché por completo el HTML de la página en el lado del cliente. Esto reducirá drásticamente el TTFB, ya que no se necesita ninguna solicitud al servidor. La desventaja es que, una vez que la página está en la caché del navegador, el usuario no verá ninguna actualización en la versión activa de la página hasta que expire la caché de la página.
Service Workers
Los service workers son scripts que se ejecutan en segundo plano en el navegador de un usuario y pueden interceptar las solicitudes de red realizadas por el navegador. Esto significa que los service workers pueden almacenar en caché recursos como HTML, imágenes, scripts y hojas de estilo, de modo que cuando el usuario regrese a tu sitio web, su navegador pueda recuperar rápidamente los recursos almacenados en caché en lugar de tener que descargarlos de nuevo.
Prefetching de páginas
Si no deseas utilizar la API Speculation Rules debido a su limitado soporte en los navegadores, podrías usar un pequeño script llamado quicklink. Esto pre-cargará todos los enlaces en la ventana gráfica visible (viewport) y casi eliminará el Time To First Byte para estos enlaces.
La desventaja de quicklink es que requiere más recursos del navegador, pero por ahora superará a la API Speculation Rules en términos de cobertura de navegadores.
Cómo mejorar el TTFB: usa un CDN
Una Red de Distribución de Contenido o CDN (Content Delivery Network) utiliza una red distribuida de servidores para entregar recursos a los usuarios. Estos servidores suelen estar geográficamente más cerca de los usuarios finales y están altamente optimizados para la velocidad. Si utilizas Cloudflare, consulta nuestra guía sobre cómo configurar Cloudflare para un rendimiento óptimo de los Core Web Vitals.
Un CDN puede ayudar a mejorar 5 de las 6 partes del Time to First Byte:
- Tiempo de redirección: La mayoría de los CDN pueden almacenar en caché las redirecciones en el borde o usar edge workers para gestionar las redirecciones sin necesidad de conectarse al servidor de origen.
- Tiempo de búsqueda de DNS: La mayoría de los CDN ofrecen servidores DNS extremadamente rápidos que probablemente superarán a tus servidores DNS actuales.
- Tiempo de conexión TCP y Handshake SSL: La mayoría de los CDN están configurados extremadamente bien y estas configuraciones, junto con la mayor proximidad a los usuarios finales, acelerarán el tiempo de conexión y el handshake.
- Respuesta del servidor: Los CDN pueden acelerar el tiempo de respuesta del servidor de varias maneras. La primera es mediante el almacenamiento en caché de la respuesta del servidor en el borde (caché en el borde de página completa), pero también ofreciendo una excelente compresión (Brotli) y los protocolos más recientes (HTTP/3).
Cómo mejorar el TTFB: evita las redirecciones
El tiempo de redirección se añade al Time To First Byte. Por lo tanto, como regla general, evita las redirecciones tanto como sea posible. Las redirecciones pueden ocurrir cuando un recurso ya no está disponible en una ubicación pero se ha movido a otra. El servidor responderá con un encabezado de respuesta de redirección y el navegador intentará en esa nueva ubicación.
Redirecciones del mismo origen (Same origin). Las redirecciones del mismo origen se originan a partir de enlaces de tu propio sitio web. Deberías tener un control total sobre estos enlaces y deberías priorizar la reparación de estos enlaces al trabajar en el Time to First Byte. Hay muchas herramientas disponibles que te permitirán verificar todo tu sitio web en busca de redirecciones.
Redirecciones de origen cruzado (Cross-origin). Las redirecciones de origen cruzado se originan a partir de enlaces en otros sitios web. Tienes muy poco control sobre estas.
Múltiples redirecciones. Las redirecciones múltiples o cadenas de redirección ocurren cuando una sola redirección no redirige a la ubicación final del recurso. Este tipo de redirecciones suponen una carga mayor para el Time to First Byte y deben evitarse a toda costa. Nuevamente, utiliza una herramienta para encontrar este tipo de redirecciones y corregirlas.
Redirecciones de HTTP a HTTPS. Una forma de sortear esto es utilizar el encabezado Strict-Transport-Security (HSTS), que forzará el protocolo HTTPS en la primera visita a un origen y luego le indicará al navegador que acceda de inmediato al origen a través del esquema HTTPS en futuras visitas.
Cuando un usuario solicita una página web, el servidor puede responder con una redirección a otra página. Esta redirección puede añadir tiempo extra al TTFB porque el navegador debe realizar una solicitud adicional a la nueva página.
Existen varias formas de evitar las redirecciones o minimizar el impacto de las mismas:
- Actualiza tus enlaces internos. Siempre que cambies la ubicación de una página, actualiza tus enlaces internos hacia esa página para asegurarte de que no queden referencias a la ubicación anterior.
- Maneja las redirecciones a nivel de servidor.
- Usa URL relativas: Al enlazar a páginas de tu propio sitio web, usa URL relativas en lugar de URL absolutas. Esto ayudará a prevenir redirecciones innecesarias.
- Usa URL canónicas: Si tienes varias páginas con contenido similar, usa una URL canónica para indicar la versión preferida de la página. Esto ayudará a prevenir contenido duplicado y redirecciones innecesarias.
- Usa redirecciones 301: Si debes usar una redirección, usa una redirección 301 en lugar de una redirección 302. Una redirección 301 es permanente, mientras que una redirección 302 es temporal. Usar una redirección 301 ayudará a prevenir redirecciones innecesarias.
Optimiza la priorización de recursos junto con el TTFB
Reducir el TTFB es solo una parte de la historia del rendimiento de carga. Una vez que llega el primer byte, el navegador necesita saber qué recursos priorizar. Lee nuestra guía de priorización de recursos para aprender cómo funcionan en conjunto las sugerencias fetchpriority, preload y preconnect con un TTFB rápido para ofrecer las cargas de página más rápidas posibles. Además, considera autoalojar tus Google Fonts para eliminar las búsquedas de DNS de terceros y los tiempos de conexión que se suman al TTFB percibido por tus usuarios.
Lo que muestran los datos de TTFB en el mundo real
Los siguientes datos provienen de CoreDash Real User Monitoring y del Web Almanac 2025.
La variación geográfica es enorme
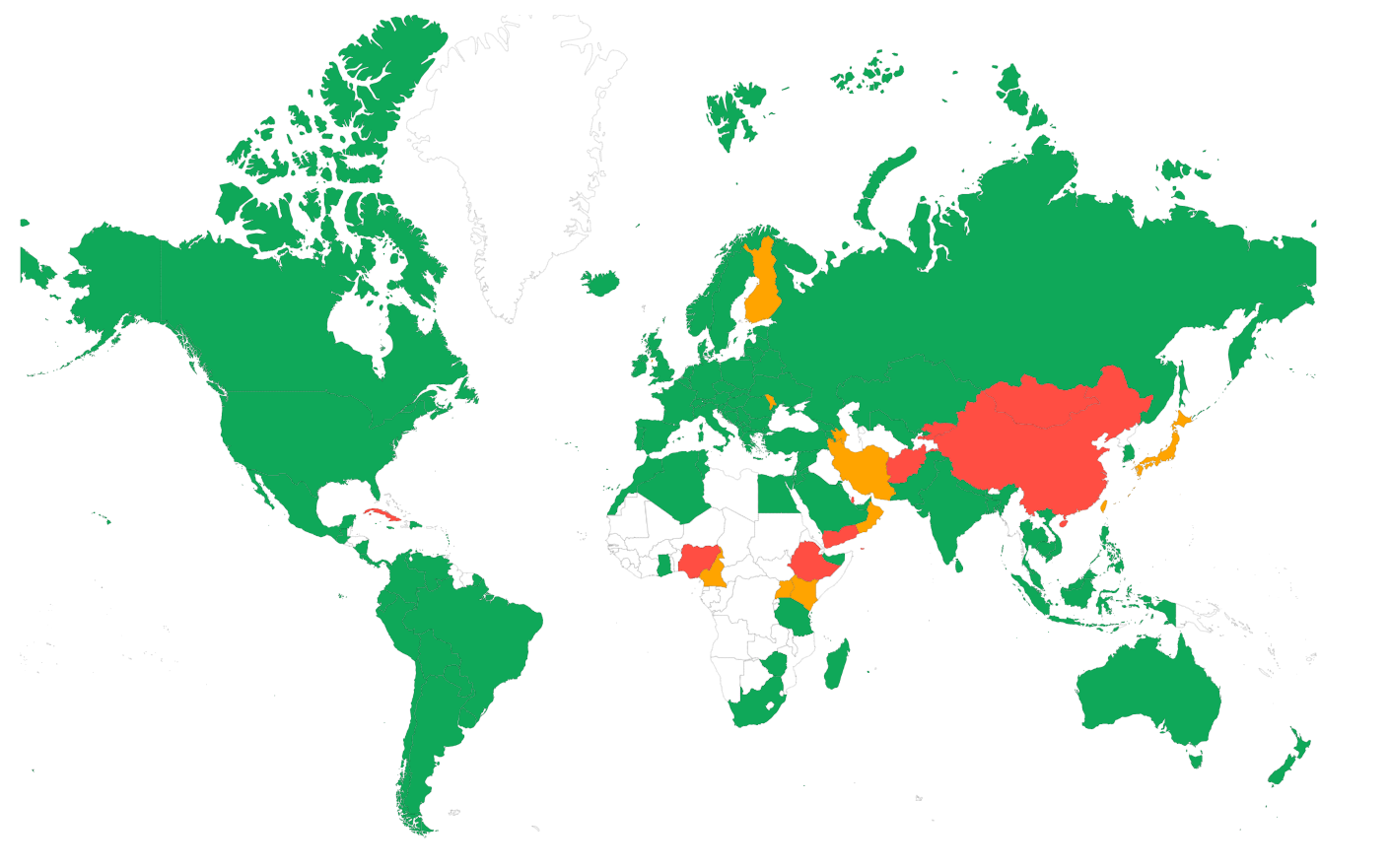
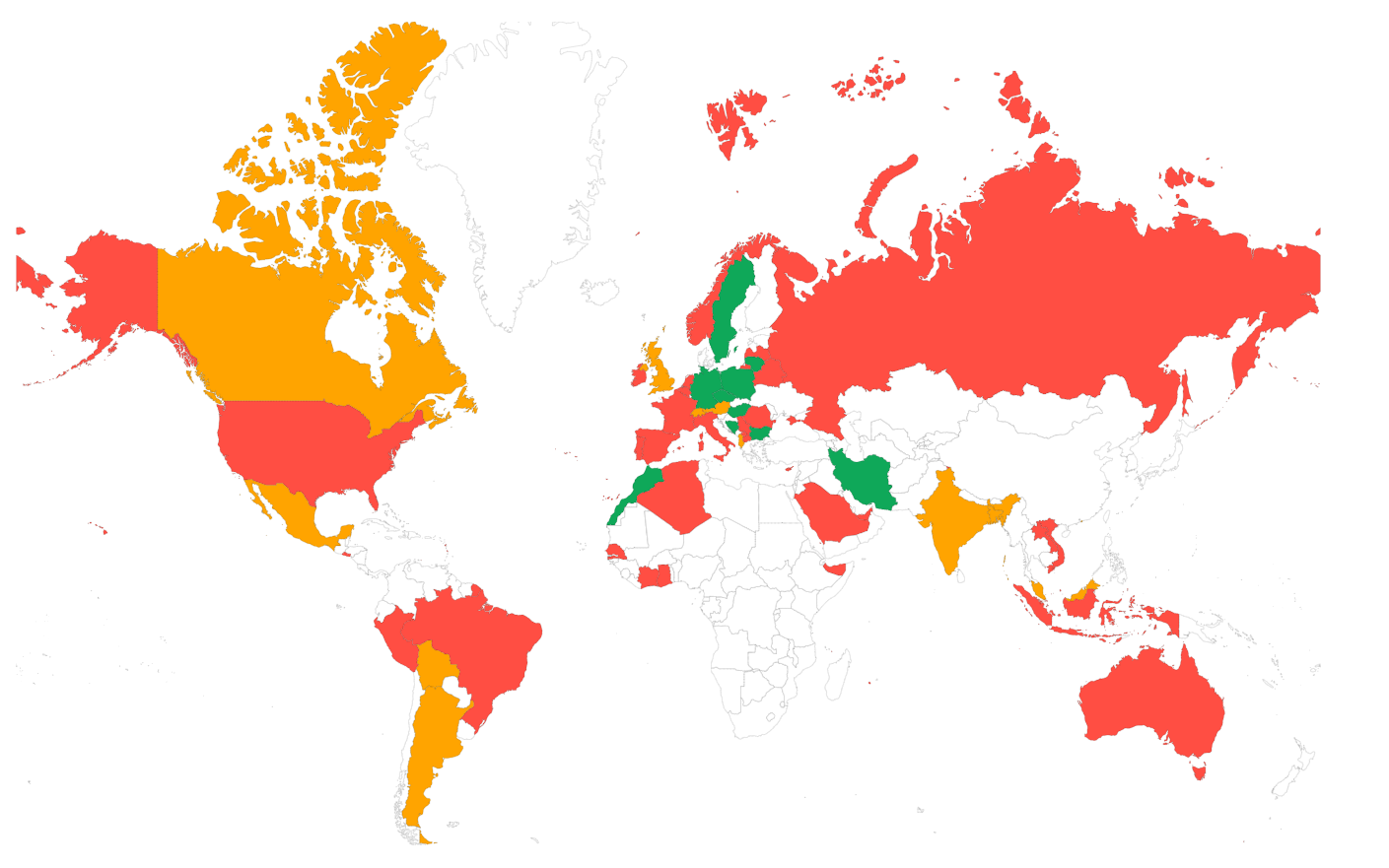
El TTFB varía drásticamente según la distancia física entre el usuario y el servidor. Los datos de CoreDash de corewebvitals.io (alojado en Europa) ilustran esto claramente:
| País | p75 TTFB | % Bueno |
|---|---|---|
| República Checa | 62ms | 98.8% |
| Países Bajos | 106ms | 97.0% |
| Alemania | 138ms | 98.5% |
| Reino Unido | 169ms | 97.7% |
| Estados Unidos | 284ms | 92.7% |
| India | 404ms | 88.2% |
| China | 1,468ms | 26.6% |
Los usuarios europeos cercanos al servidor ven un TTFB por debajo de 170ms, mientras que los usuarios en India experimentan un TTFB 3 veces mayor y los usuarios en China ven un TTFB casi 10 veces mayor (1468ms) debido al Gran Cortafuegos (Great Firewall) y a la gran distancia física. Estos datos demuestran por qué un CDN con ubicaciones de borde globales es esencial para audiencias internacionales.
El pre-renderizado de Speculation Rules ofrece un TTFB de 0ms
Los datos del tipo de navegación de CoreDash confirman que las páginas pre-renderizadas mediante Speculation Rules logran un TTFB en el percentil 75 de 0 milisegundos. Las navegaciones estándar miden 131 ms, las recargas se sitúan en 82 ms (beneficiándose de las conexiones activas) y las navegaciones de retroceso-avance son las más lentas con 244 ms. Esto convierte a las Speculation Rules en la técnica individual más eficaz para eliminar el TTFB en las cargas de página posteriores.
El TTFB en móvil es 2,5 veces el de escritorio
En corewebvitals.io, los usuarios móviles experimentan un TTFB p75 de 316 ms, frente a los 124 ms en escritorio. Esta brecha de 2,5x está causada por la latencia de la red móvil, no por diferencias en el servidor. Solo el 88,5 % de las cargas de páginas móviles alcanzan una calificación de TTFB "buena" en comparación con el 96,1 % en escritorio. Cuando optimices el TTFB, prueba siempre en redes móviles reales.
Los visitantes nuevos y recurrentes ven un TTFB similar
En este sitio, los visitantes nuevos ven un TTFB p75 de 127 ms, mientras que los recurrentes ven 138 ms. La similitud sugiere que un almacenamiento en caché consistente del lado del servidor (en lugar de las ventajas de la caché del lado del cliente) es el factor principal en el rendimiento del TTFB. En sitios sin almacenamiento en caché del lado del servidor, la brecha entre visitantes nuevos y recurrentes puede ser mucho mayor.
El TTFB global se ha estancado durante 5 años
Según el Web Almanac 2025, solo el 44 % de las páginas móviles logran una puntuación de TTFB "buena" a nivel mundial. Este número apenas ha cambiado desde el 41 % en 2021, lo que convierte al TTFB en la métrica de rendimiento más estancada en la web. Mientras tanto, el LCP mejoró del 44 % al 59 % y el INP del 55 % al 74 % durante el mismo período. Los sitios con un LCP deficiente pasan un promedio de 2,27 segundos solo en el TTFB, casi la totalidad del umbral de 2,5 segundos del LCP.
Preguntas frecuentes sobre el TTFB
¿Qué es un buen TTFB?
Un buen Time to First Byte es de 800 milisegundos o menos en el percentil 75. Esto significa que el 75 % de tus usuarios debería recibir el primer byte de la respuesta en menos de 800 ms. Un TTFB de entre 800 ms y 1800 ms necesita mejorar, y un TTFB superior a 1800 ms se considera deficiente. Ten en cuenta que estos umbrales se aplican al TTFB de navegación completo, que incluye el DNS, el TCP, el TLS y el tiempo de procesamiento del servidor.
¿Es el TTFB un Core Web Vital?
No, el TTFB no es un Core Web Vital. Los tres Core Web Vitals son el Largest Contentful Paint (LCP), la Interaction to Next Paint (INP) y el Cumulative Layout Shift (CLS). El TTFB se clasifica como una métrica de diagnóstico. No se utiliza directamente en las señales de clasificación de la experiencia de página de Google, pero tiene un impacto indirecto importante porque un TTFB lento incrementa directamente tanto el LCP como el FCP. Optimizar el TTFB suele ser la forma más rápida de mejorar tus puntuaciones de los Core Web Vitals.
¿Cómo reduce un CDN el TTFB?
Un CDN (Content Delivery Network) reduce el TTFB de varias maneras. En primer lugar, ubica servidores geográficamente más cerca de tus usuarios, lo que reduce la latencia de la red para las búsquedas de DNS, las conexiones TCP y los handshakes TLS. En segundo lugar, un CDN puede almacenar en caché tus páginas en servidores de borde (edge servers) para que la respuesta pueda servirse sin necesidad de conectarse a tu servidor de origen. En tercer lugar, los CDN suelen ofrecer configuraciones altamente optimizadas que incluyen HTTP/3, compresión Brotli y una rápida negociación TLS. Los datos de CoreDash muestran que los usuarios cercanos al servidor (República Checa: 62 ms) experimentan un TTFB drásticamente menor que los usuarios lejanos (India: 404 ms, China: 1468 ms).
¿Cuál es la diferencia entre el TTFB y el tiempo de respuesta del servidor?
El tiempo de respuesta del servidor solo mide el tiempo que el servidor pasa procesando la solicitud y generando la respuesta. El TTFB incluye el tiempo de respuesta del servidor más toda la sobrecarga de la red: resolución de DNS, conexión TCP, handshake TLS y el tiempo de tránsito de la red tanto para la solicitud como para el primer byte de la respuesta. Un sitio puede tener un tiempo de respuesta de servidor rápido (medido a través de la API Server-Timing) pero aun así tener un TTFB lento si el usuario está lejos del servidor o en una red lenta. Al depurar problemas de TTFB, es importante desglosar la métrica en sus subpartes para determinar si el problema está en el lado del servidor o en el lado de la red.
¿Por qué mi TTFB es alto para algunos países?
El TTFB varía según el país debido a la distancia física, a la calidad de la infraestructura de la red y al enrutamiento de Internet. Cada subparte del TTFB (DNS, TCP, TLS, respuesta del servidor) se ve afectada por el tiempo de viaje de ida y vuelta entre el usuario y el servidor. Un usuario en la India que se conecta a un servidor en Alemania experimentará varios viajes de ida y vuelta a través de miles de kilómetros, cada uno de los cuales añadirá latencia. Los países con una infraestructura de Internet menos desarrollada o con cortafuegos restrictivos (como China) experimentan un TTFB aún mayor. La solución consiste en utilizar un CDN que almacene tu contenido en caché en servidores de borde cercanos a tus usuarios, o en desplegar tu aplicación en varias regiones.
Guías relacionadas: Subpartes del TTFB
Cada subparte del Time to First Byte tiene sus propias estrategias de optimización:
- <b>Identificar y solucionar problemas de TTFB</b>: una guía de diagnóstico paso a paso para encontrar la causa principal de un TTFB lento utilizando DevTools, Server-Timing y datos RUM.
- <b>Reducir el tiempo de espera (Waiting Duration)</b>: cómo minimizar el tiempo de redirección y los retrasos en el procesamiento del servidor que se suman a tu TTFB.
- <b>Reducir la duración de la caché (Cache Duration)</b>: estrategias para la caché del navegador, los service workers y la caché de avance/retroceso (bfcache) para eliminar el TTFB de los visitantes recurrentes.
- <b>Minimizar la duración del DNS (DNS Duration)</b>: cómo acelerar la resolución DNS con proveedores de DNS más rápidos, mayores valores de TTL y sugerencias de recursos (resource hints)
dns-prefetch. - <b>Optimizar la duración de la conexión (TCP + TLS)</b>: cómo reducir el tiempo de handshake TCP y TLS con HTTP/3, TLS 1.3, reanudación de sesión y sugerencias
preconnect.
Entérate de qué va lento de verdad.
Trazo tu critical rendering path con datos reales. Te paso una lista de fixes priorizada. No otro informe de Lighthouse.
Quiero la auditoría
